


매일 같이 새로운 LLM이 공개되는 지금, 우리는 쏟아지는 LLM 속에서 어떻게 나에게 딱 맞는 모델을 찾을 수 있을까요?
또 우리는 어떻게 “말을 잘 한다” 는 기준을 수치화할 수 있을까요?
금융기술연구소가 if(kakaoAI) 2024에서 발표한 카카오뱅크 시선에 맞춘 LLM을 평가 및 검증 능력의 내재화 경험을 공유합니다.
생성형 AI의 황금기 : 끝없이 등장하는 LLM과 평가 방법들
Language Model 기술이 변곡점을 넘어가면서 LLM을 이용한 새로운 모델들과 LLM에 관한 연구 결과들이 폭발적으로 발표되고 있습니다. 특히 ACL(Association for Computational Linguistics) 학회의 Language Model 관련 논문의 발표 추이를 보면 그 관심을 시간이 지날수록 더더욱 증가하는 것을 알 수 있습니다. 또한 Hugging Face의 Text Generating 분야도 2년 만에 46배 성장하여 이는 비단 학술적인 접근뿐만이 아니라 학계와 산업계의 관심이 지속적으로 확산되고 있음을 보여줍니다.
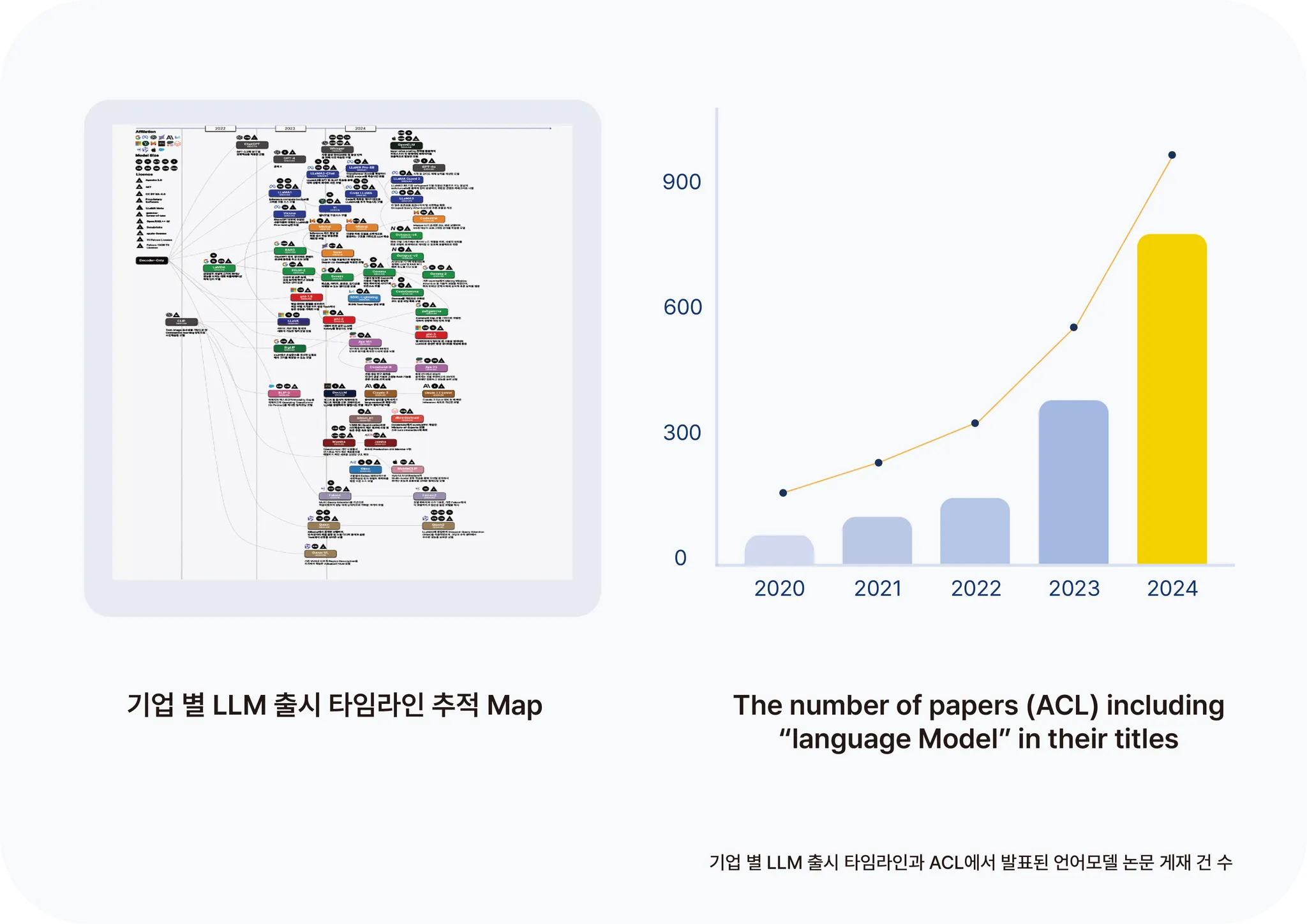
이렇게 많은 선택지가 쏟아지면 자연스럽게 "어떤 모델이 가장 좋을까?"라는 질문이 생깁니다. 그 배경에는 각 서비스와 데이터가 모두 다르고 필요한 속도, 환경, 성능 등 다양한 요인들을 고려해야 하기 때문입니다. 모델 선택은 이러한 요소들을 종합적으로 고려해야 하는 복잡한 과정이며 특정 상황에 가장 적합한 모델을 선택하기 서비스 별 특화 기준이 필요합니다.
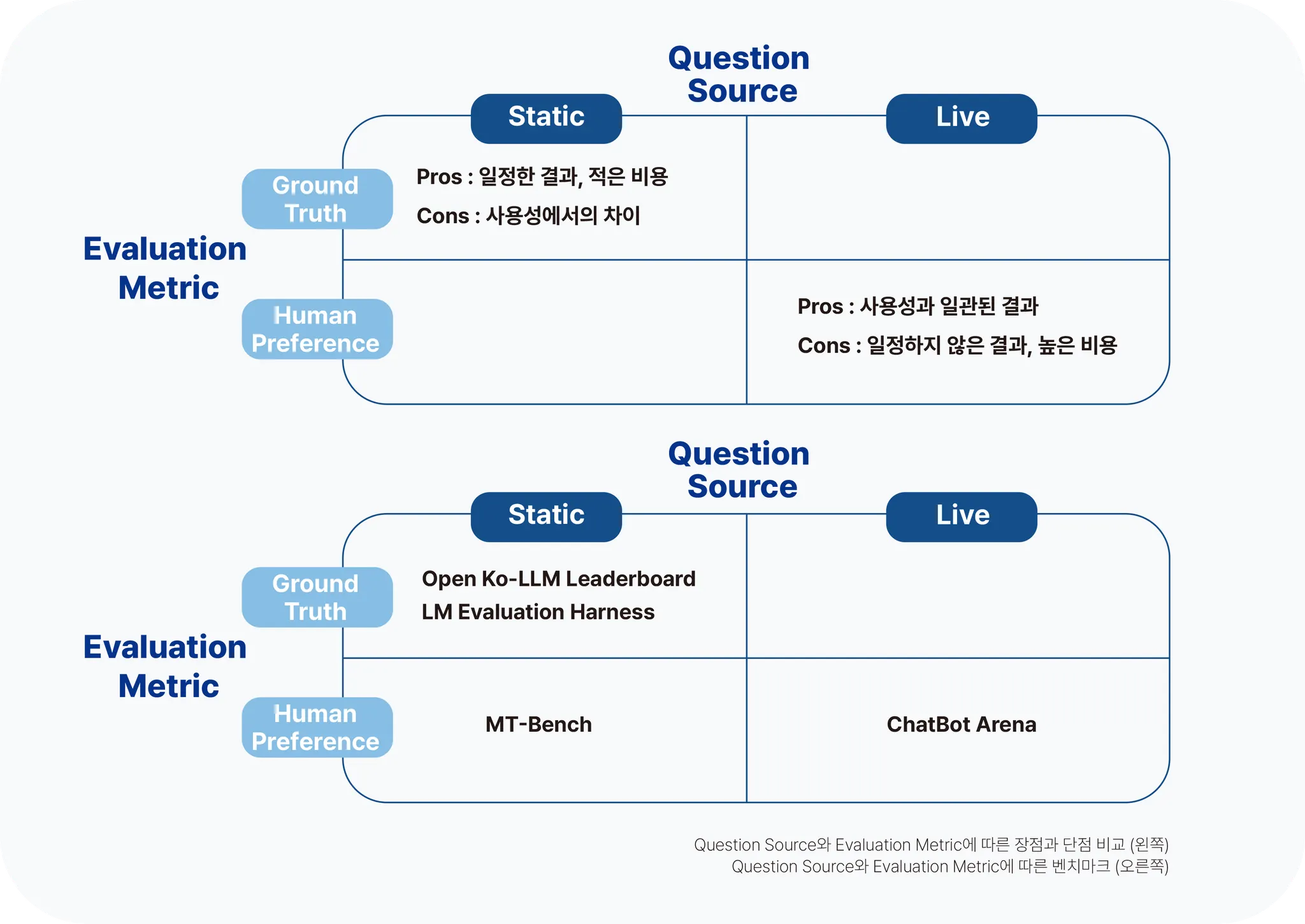
일반적으로 LLM의 성능을 확인하기 위해서는 현재 공개되어 있는 Open Ko-LLM LeaderBoard, LM Evaluation Harness 등의 벤치마크를 활용하여 기준을 수립하는 방법이 있습니다. 이러한 방법은 이미 공개되어 있는 데이터를 이용하기에 쉽고 빠르게 측정이 가능하다는 장점이 있으나, 정답(Ground Truth)이 있는 벤치마크 특성상 서비스에 따라 측정된 성능과 실제 사용성이 다소 차이가 있는 한계가 있습니다. 그렇기 때문에 Chatbot Arena, MT-Bench(Judging LLM-as-a-Judge) 등을 이용해 사람의 선호도(Human Preference)와 유사하게 성능을 측정하여 실제 사용성을 일치시키는 방법을 사용합니다. 하지만 마찬가지로 측정자의 선호에 따라 일관적이지 않은 측정 결과가 출력될 수 있는 등 한계가 존재합니다.
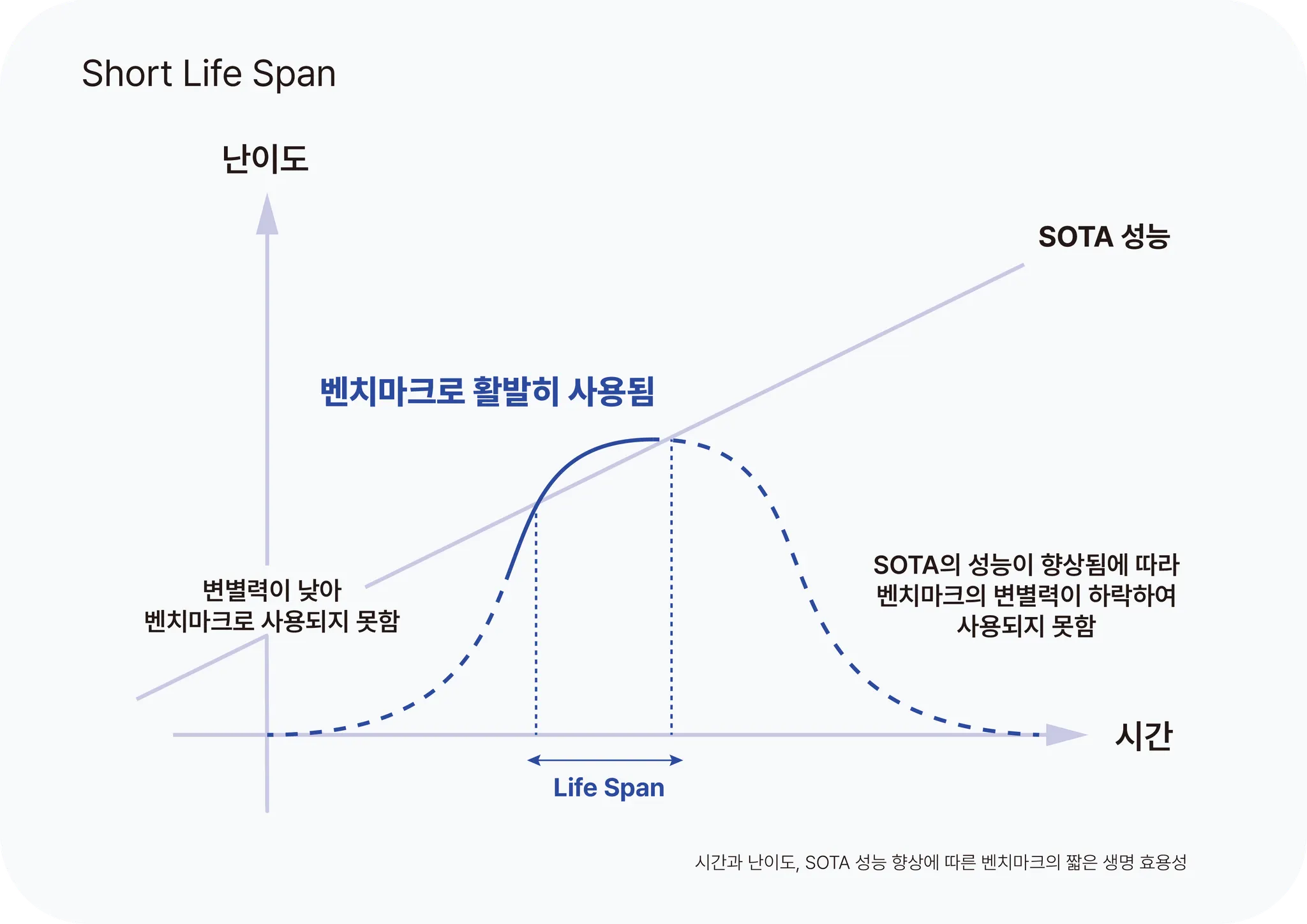
또한 시중에 공개된 벤치마크에는 각 벤치마크 특성마다 고유의 한계뿐만 아니라, "제한된 범위"와 "짧은 수명 주기"라는 공통된 문제도 존재합니다. 특히 SOTA 모델의 성능이 고도화될수록 벤치마크가 너무 어렵지도, 너무 쉽지도 않아야 하는 특성 때문에 그 수명이 매우 짧아집니다. 짧은 수명은 최신 모델의 평가와 비교를 위해 지속적으로 새로운 벤치마크가 필요하다는 것을 의미하며, 벤치마크를 설계하고 유지하는 데 더 많은 시간과 자원이 필요합니다. 따라서 더 지속 가능하고 포괄적인 벤치마크를 개발하는 것이 중요한 과제로 떠오릅니다.
DUO (A Diverse Understanding and Observation of LLMs) 프로젝트 주요 내용 소개
다양한 한계점을 극복하고 모델을 선택 시 보다 효율적이고 카카오뱅크 특성을 반영하기 위해 LLM 평가 프레임워크 및 벤치마크를 개발하였습니다.
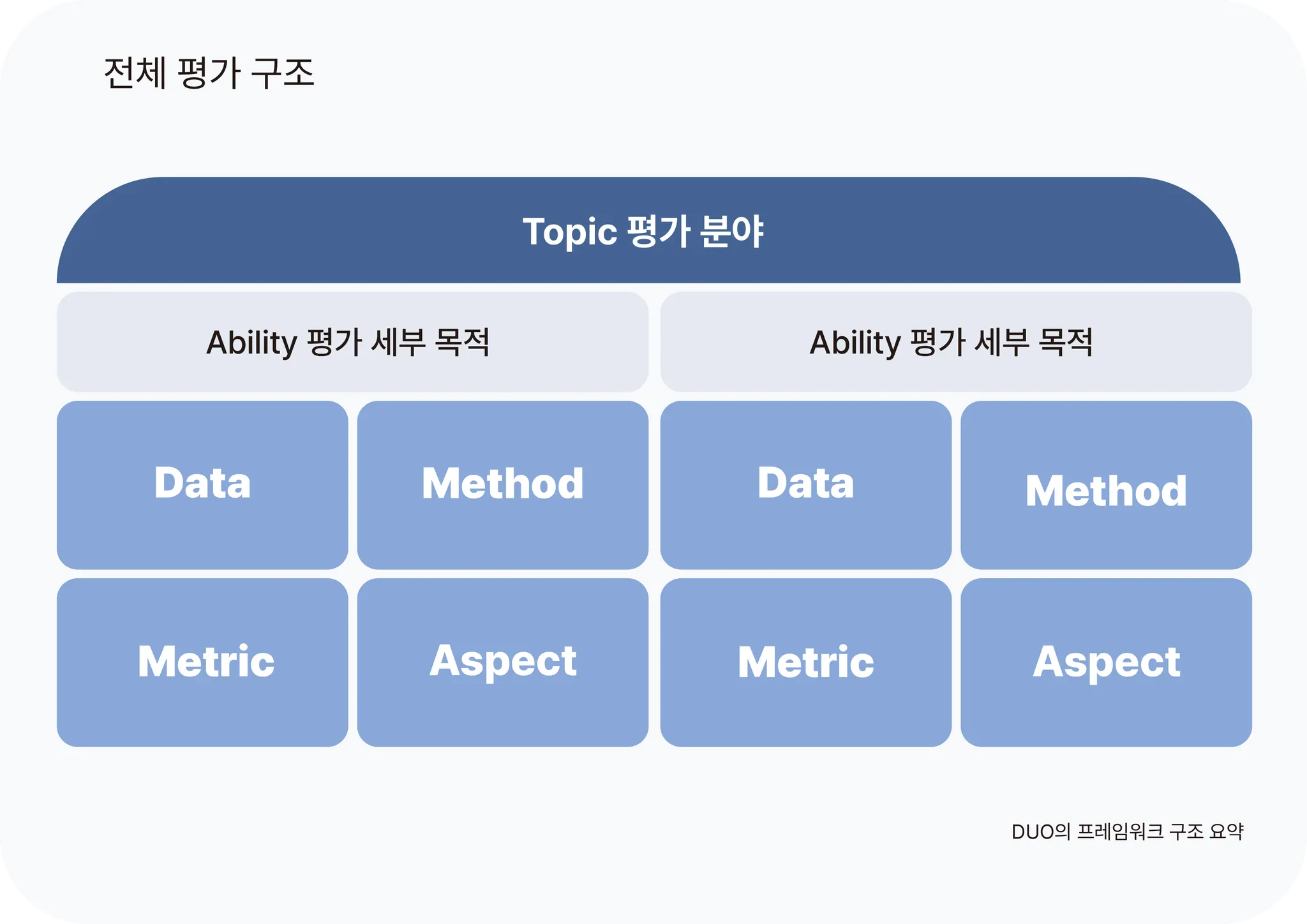
DUO는 크게 5가지 구조로 구성되어 있습니다.
•
Topic : 평가 분야
•
Ability : 평가 세부 목적 ( = LLM의 보유 능력 )
•
Data : Ability를 측정하기 위한 평가 기준 벤치마크
•
Method : Ability를 측정하기 위한 평가 방법론
•
Metric : Method를 수행하여 얻은 객관적 수치 및 해석
DUO는 현재 금융 분야와 범용 분야를 포함하여 총 5가지 Topic으로 구성되어 있으며, 그중 금융 분야의 2가지 Topic인 FCA(Financial Calculation Accuracy, 금융분야 계산 정확도)[1] 와 FMT(Financial Multi Turn, 금융분야 멀티 턴 대화 능력)은 금융 데이터의 정밀한 계산 능력과 복잡한 대화 시나리오에서의 성능을 평가합니다. 특히 FCA는 금융 계산의 정확도를 측정함으로써 실무에서 발생할 수 있는 오류를 최소화하고, 신뢰성을 높이는 데 중점을 둡니다. 반면 FMT는 사용자와의 다중 턴 대화에서 정확하고 자연스러운 응답을 생성함으로써 사용자 경험을 향상하는 데 목적이 있습니다. 이를 통해 DUO는 다양한 금융 서비스를 위한 AI 모델의 성능을 종합적으로 평가하여 모델 도입 시 발생하는 다양한 시행착오를 줄이고, 성능을 개선하는 데 중점을 두고 있습니다.
1) Financial Calculation Accuracy 금융분야 계산 정확도
금융 서비스에서의 숫자 계산은 다양한 서비스로 확장이 가능하기에 꾸준히 주목받는 분야이지만, LLM의 숫자 계산 능력은 아직 많은 고민이 남아 있습니다. 이를 카카오뱅크의 관점에서 해석하고자 금융 전문 용어와 한국어의 다양한 숫자 표기법이 성능에 미치는 영향도 함께 검증하였습니다. 보다 구체적으로는 카카오뱅크의 대표 금융 서비스인 예금·적금·대출 영역에서의 계산 능력과 카드 영역의 대소 비교 능력을 검증했고, 아래 그림과 같이 평가 프로세스를 구성했습니다.
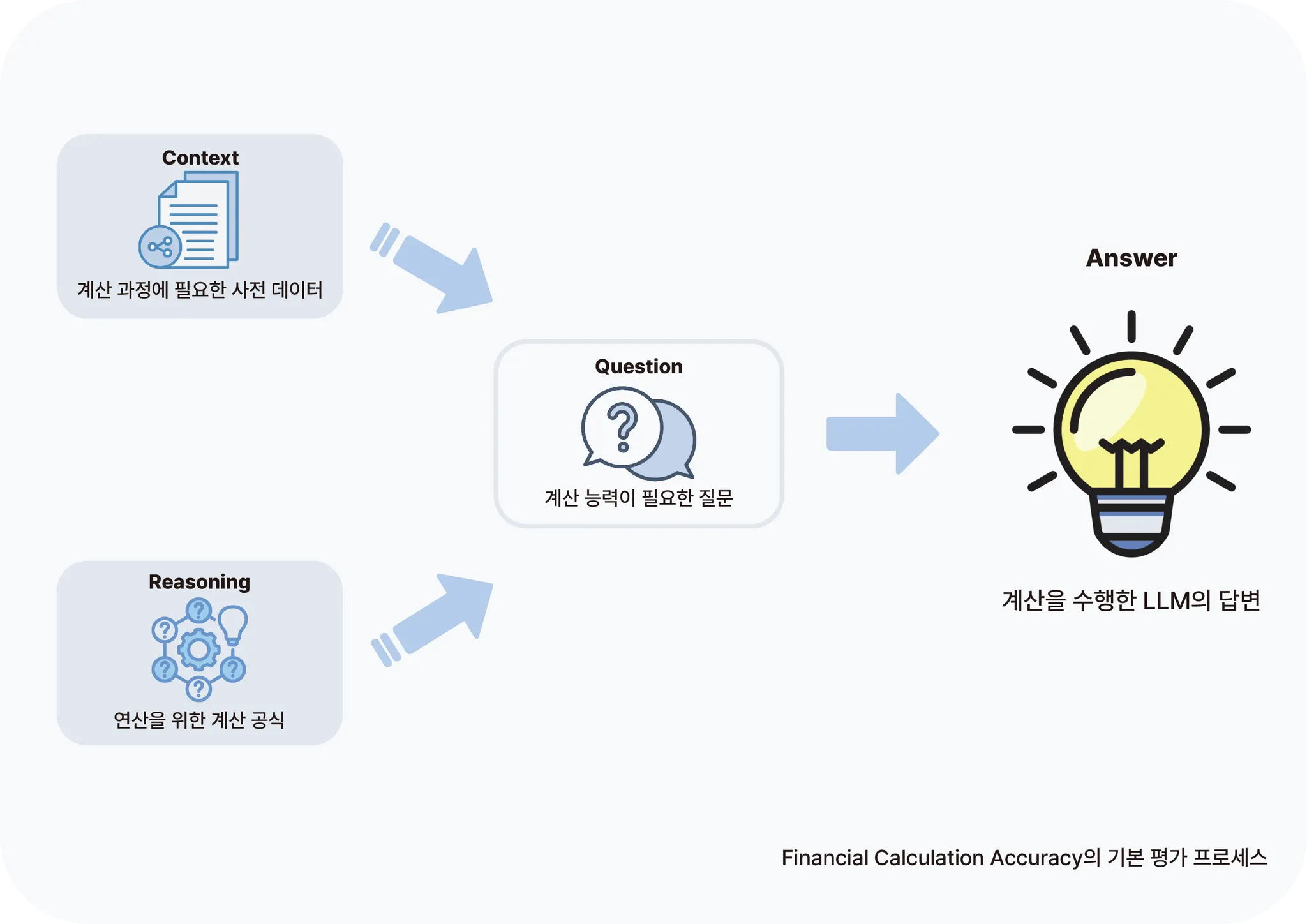
2) Financial Multi Turn, 금융분야 멀티 턴 대화 능력
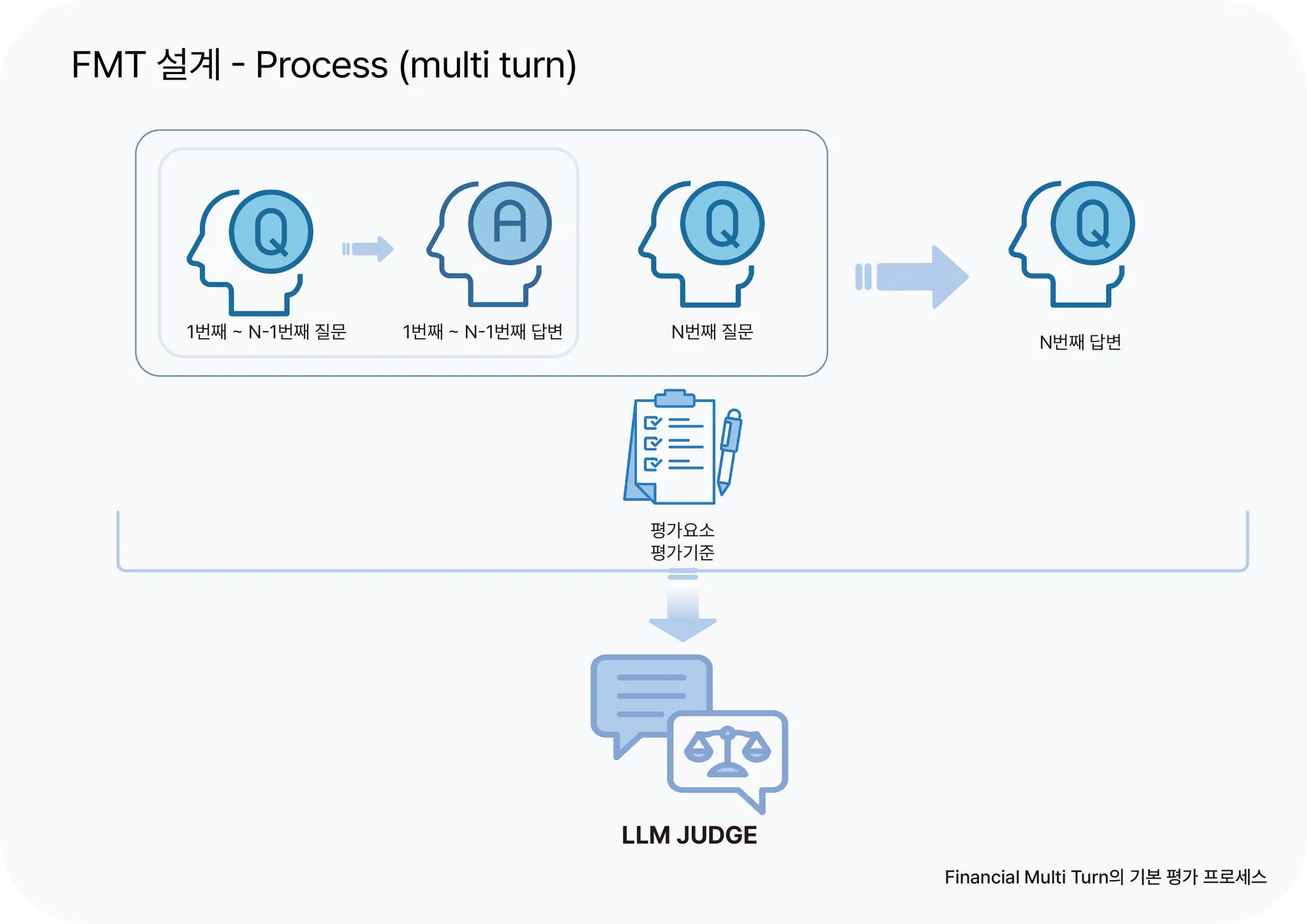
최근 AI 서비스는 서비스 제공자가 제어하던 방식에서 벗어나, 사용자 중심의 맥락을 가진 검색·추천·챗 서비스로 전환되고 있습니다. 이 과정에서 가장 중요한 요소 중 하나는 질문이 바뀌더라도 유연하게 맥락을 유지하며 정확한 정보를 전달할 수 있는 멀티턴 대화 능력입니다. 이러한 멀티턴 대화 능력을 검증하기 위해서 고객센터 롤 플레잉, 세법 판례 해석 등 다양한 시나리오에서 멀티턴 대화 능력을 검증하였습니다. 또한 성능이 우수한 LLM을 이용해 사전 정의한 기준에 맞게 평가하는 LLM Judge 방식으로 "대화를 잘 한다는 것"을 수치화하여 일관적인 성능을 확보하고 Ground Truth, Human Preference의 한계를 극복하였습니다.
멀티턴 상황에서 대화의 연속성 평가를 반영하기 위해, 사용자가 다음 질문을 할 때마다 앞서 수행된 질의응답을 앞부분에 입력해 주었습니다. 멀티턴 LLM 능력 평가는 마지막 답변을 기준으로 앞선 대화의 맥락을 잘 유지했는지까지 확인했습니다.
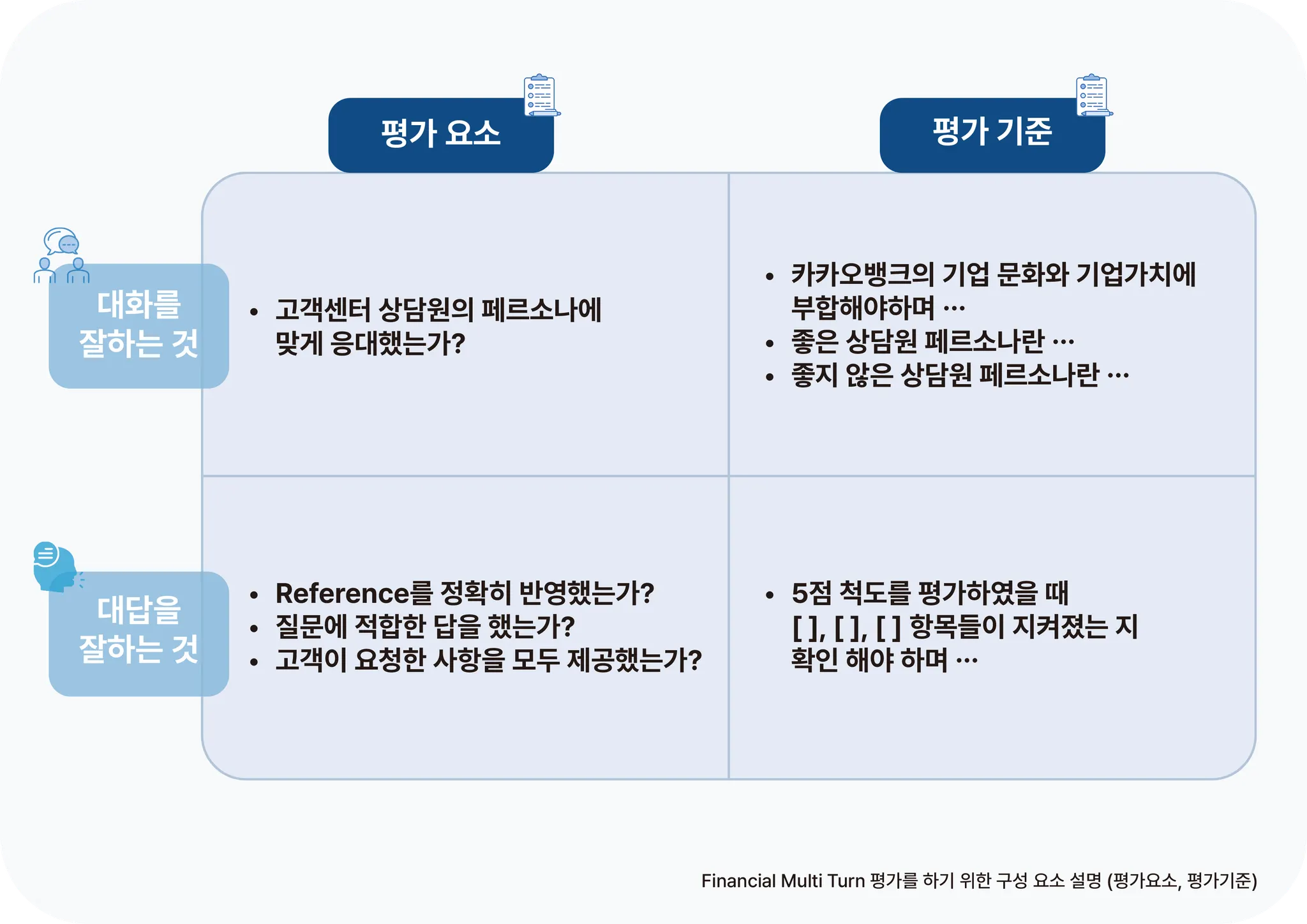
또한 “대화를 잘 하는 것” 과 “대답을 잘 하는 것”을 분리하여 평가 요소와 기준을 수립하였습니다. 대화를 잘 하는 것은 답변 내용의 자연스러움과 페르소나에 맞는 역할과 톤을 유지하는지가 중요했으며, 대답을 잘하는 것은 정확한 정보 전달과 지시 사항을 누락 없이 모두 수행했는지 여부를 비교했습니다.
DUO 실행 결과
이렇게 구축된 5개의 평가 분야(Topic)와 약 30개의 세부 항목(Ability)으로 보편적으로 좋은 성능을 확보한 LLM을 찾기 위해 가장 많이 사용되는 21가지 모델을 평가하였습니다. 또한 성능 측정 결과를 분석 시 “파라미터 사이즈와 성능의 상관성”을 추가적으로 확인하기 위해 파라미터 사이즈와 성능 평균 점수를 시각화하였습니다. 시각화 결과 그래프 상에서 확인되다시피 대체적으로는 파라미터 사이즈와 성능이 양의 상관관계를 보이지만, 평균 점수 이상부터는 다른 경향성을 보여줍니다. 더불어 상위 20% 모델들은 보다 더 다른 경향성을 보여줍니다.
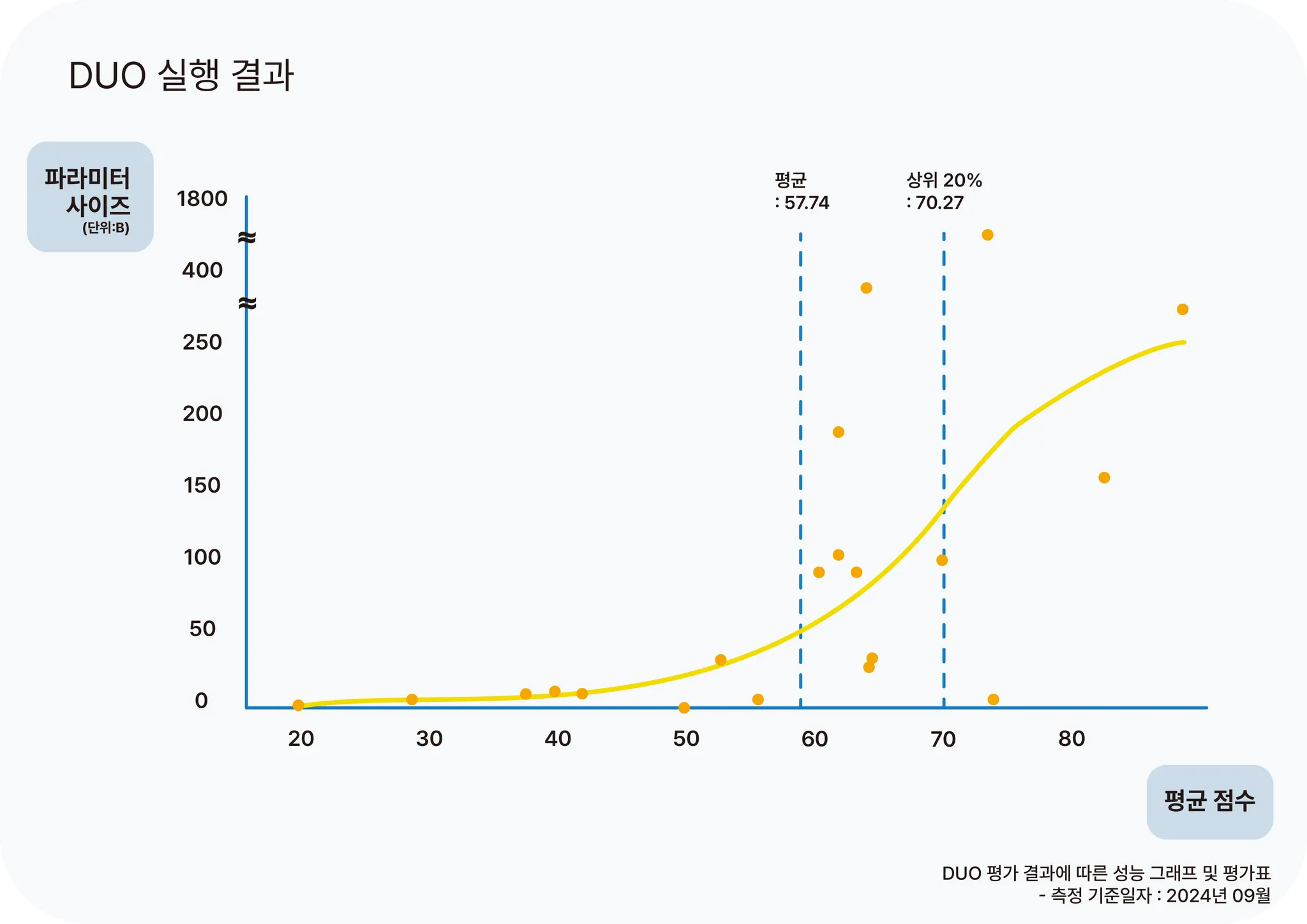
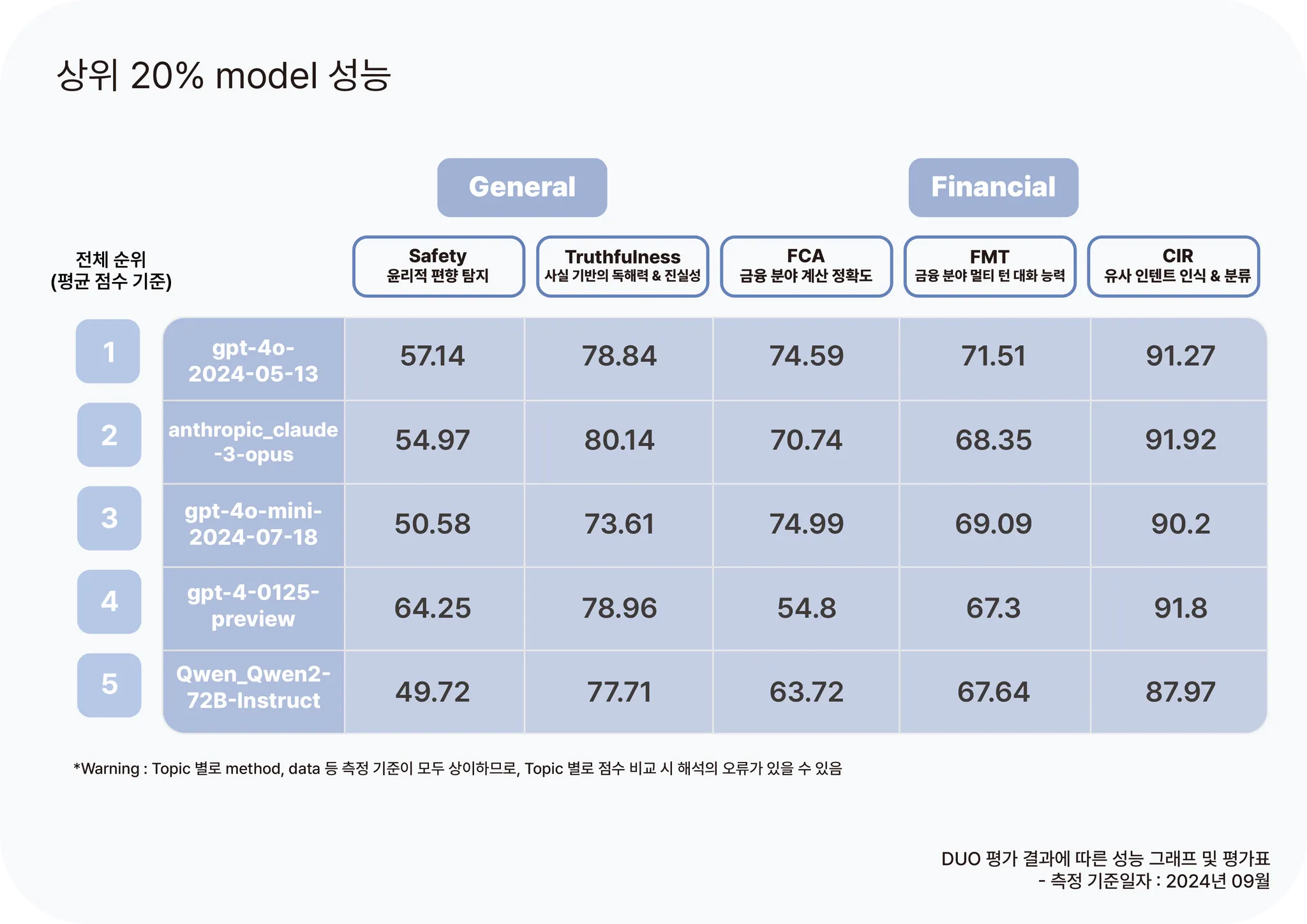
결과적으로, 성능을 측정한 21개 LLM 모델 중 대체로 GPT 기반 모델들이 우수한 성능을 보였습니다. 특히 GPT-4o는 5개 Topic에서 모두 1~3등의 좋은 성과를 거두었으며, GPT-4o mini는 약 200배 이상 파라미터 사이즈 차이가 나는 GPT4보다 FCA Topic에서 20점 이상 높은 성능을 보였습니다.(측정 기준일 2024년 09월) 이로써 "파라미터 사이즈와 성능의 상관성"은 적정 성능 이상에서는 낮은 상관관계를 보였고, 오히려 모델의 최신성과 높은 상관관계를 보였습니다. 따라서 현재 시점에서 LLM을 이용한 서비스 개발 시, 최신 버전으로 유연하게 교체할 수 있는 개발 아키텍처가 필요한 시기임을 확인할 수 있었습니다.
이처럼 폭발적인 LLM 시대에는 다양한 관점에서 LLM을 평가하는 능력이 점점 더 중요해지고 있습니다. 모델 성능이 고도화되고 LLM을 활용한 서비스들이 확장될수록 전문 분야에 맞는 적합한 해석과 검증이 지속적으로 요구될 것이라 생각되며, 금융을 넘어 제조·법률 등 다양한 분야에서 평가 프레임워크에 대한 고민이 모델만큼이나 필수적이게 될 것입니다. 이러한 배경 속에서, 저희의 모델 평가 내재화 경험이 If(kakaoAI) 2024를 시작으로 더 많은 특화 모델과 맞춤형 해석 방법을 발전시키는 데 기여할 수 있기를 바랍니다.
Reference
[1] Expertise-Centric Prompting Framework for Financial Tabular Data Generation using Pre-trained Large Language Models, Subin Kim, Jungmin Son, and Youngjun, NeurIPS 2024 3rd TRL workshop.
카카오뱅크 금융기술연구소
Financial Tech Lab