

안정성과 혁신 모두를 위해 도약하는 우리의 이야기를 담았습니다


금융기술연구소에서는 Multi-Agent System(MAS) 이 실제 금융 의사결정 환경에서 어떤 효용을 가질 수 있는지 검증하기 위해, 약 3개월간 PoC를 진행했습니다.
이번 연구는 단순히 성능 비교를 넘어서, 에이전트 간 협업 구조를 어떻게 설계해야 효과적인지, 그리고 MAS의 성능을 어떻게 평가하고 설명할 수 있는지에 대한 실질적인 인사이트를 도출하는 것을 목표로 했습니다.
1. 왜 MAS였을까?
MAS 프로토타입 구현 과정 및 결과 인사이트 공유
2026/07/14
연구과제


Part 1. AI Observability란 무엇인가
(1) Observability란?
Observability는 소프트웨어 분야에서 사용되는 개념으로, 우리말로는 ‘관찰 가능성’이라고 합니다. 단순히 시스템을 감시하는 것을 넘어, 시스템이 실제로 어떻게 동작하고 있는지를 이해할 수 있게 하는 것을 의미합니다. 로그·메트릭·트레이스와 같은 다양한 신호를 활용해, 단순히 “문제가 있다”를 넘어 “왜 그런 결과가 나왔는지”까지 추론할 수 있게 합니다.
자주 함께 언급되는 개념은 Monitoring입니다. Monitoring은 사전에 정해 둔 지표와 임계값(예: 응답시간, 에러율)을 기준으로 시스템이 정상 범위를 벗어났는지 감지하고 알람을 울리는 활동입니다. ‘무엇이, 언제 잘못됐는지’를 빠르게 알려 줍니다. Observability는 Monitoring을 포함하면서, 한 걸음 더 나아가 ‘왜 그런 결과가 나왔는지’까지 따라갈 수 있게 합니다. 이상을 감지하는 단계’를 넘어 ‘원인을 이해하는 단계’까지 아우릅니다.
AI Observability: 대화형 AI의 '진짜' 문제를 찾는 법
2026/07/06
연구과제


LREC 2026에서 인정받은 카카오뱅크의 금융 수치 추론 기술력
카카오뱅크 기술연구소의 논문 <BankMathBench: A Benchmark for Numerical Reasoning in Banking Scenarios>가 자연어 처리(NLP) 분야의 대표 국제 학회인 LREC 2026에 구두 발표(Oral Presentation)로 채택되었습니다.
BankMathBench는 예적금, 대출 등 실제 은행 상품 시나리오에서 필수적인 수치 계산 및 추론 능력을 평가하기 위해 설계된 금융 수치 추론 특화 벤치마크입니다. 언어 데이터셋과 평가 방법론을 핵심적으로 다루는 LREC에서 이번 연구가 채택된 것은, 카카오뱅크가 단순히 AI 모델을 활용하는 단계를 넘어 금융 AI의 정확도와 신뢰성을 검증할 수 있는 표준을 제시했다는 점에서 큰 의미가 있습니다. 카카오뱅크는 이번 연구를 통해 일상 금융 시나리오에서의 수치 추론 능력을 체계화하고, 실제 모델의 성능 개선 효과까지 실험적으로 입증하며 금융 AI 기술력을 증명했습니다.
연구 배경 및 주요 성과 : 뱅킹 시나리오 특화 벤치마크 제안 및 주요 성과
BankMathBench: A Benchmark for Numerical Reasoning in Banking Scenarios
2026/05/14
논문


세계 최고 권위의 인공지능 학회인 ICLR 2026(International Conference on Learning Representations)에 카카오뱅크 기술연구소가 카이스트와의 산학협력을 통해 연구한 전문 분야 가드레일 <EXPGUARD: LLM Content Moderation in Specialized Domains> 논문이 포스터 세션으로 채택되었습니다.
ICLR은 Google, Meta, OpenAI 등 글로벌 AI 선도 기업들이 참여하여 미래 AI의 방향성을 만들어가는 Top3 국제 학술 대회입니다. 약 28%라는 높은 경쟁률을 뚫고 채택된 이번 연구는 카카오뱅크가 단순히 AI 모델을 사용하는 것을 넘어, AI의 안전성을 제어하는 'AI Safety' 분야에서 글로벌 수준의 기술력을 보유하고 있음을 입증한 결과입니다.
왜 가드레일에 '전문 도메인(Specialized Domains)' 이 필요할까?
ICLR 2026에서 인정받은 카카오뱅크의 AI Safety 기술력, 프롬프트 어택 탐지 가드레일 EXPGUARD
2026/05/06
논문


LREC 2026에서 입증한 멀티모달 울타리, “안으로 들어오면 안전해요”
최근 몇 년간 우리 일상에 깊이 자리 잡은 LLM은 텍스트를 넘어 이미지, 음성 등 다양한 영역으로 빠르게 확장되고 있습니다. 그 중 이미지를 함께 이해하는 모델을 비전 언어 모델 (Vision Language Model, VLM)이라고 부릅니다.
하지만 모델이 고도화될수록 보안 위협도 함께 진화합니다. 대표적인 사례가 바로 탈옥 공격(Jailbreak Attack)으로, 교묘하게 조작된 텍스트나 이미지로 모델의 안전장치를 우회해 민감한 정보를 끌어내는 공격을 의미합니다. 고객의 자산과 민감 데이터가 오가는 금융 AI에서 이를 막을 방어 체계는 이제 선택이 아닌 필수입니다.
저희는 금융 AI를 탈옥 공격으로부터 지켜내기 위해 금융 분야의 멀티모달 탈옥 공격 탐지 데이터셋인 FENCE를 구축했습니다. 이 연구를 담은 논문 〈FENCE: A Financial and Multimodal Jailbreak Detection Dataset〉은 자연어 처리 분야의 대표 국제 학회인 LREC 2026에 채택되었으며, 이번 글에서 그 내용을 소개하고자 합니다.
FENCE: A Financial and Multimodal Jailbreak Detection Dataset
2026/04/28
논문


연구배경
금융권에서 AI 기반 고객 서비스가 확대되면서 정확한 정보 검색(Information Retrieval; IR)의 중요성이 커지고 있습니다. 특히 은행은 상품 안내부터 약관 설명까지 다양한 고객 문의를 처리하기 위해 정교한 IR 시스템이 필요합니다. 하지만 기존 금융 정보 검색 벤치마크는 몇 가지 한계가 있었습니다.
•
주로 재무제표가 뉴스 분석에 집중되어 있어 실제 은행 업무에 적용하기 어려움
•
여러 문서를 참조해야 하는 복잡한 질의가 부족
ICAIF 2025: RAG를 위한 텍스트 임베딩 모델 개발
2025/12/15
논문


모바일 신분증 시대, 카카오뱅크가 금융권 최초로 신뢰성을 입증하다 
카카오뱅크는 지난 9월 한국정보통신기술협회(이하 TTA)가 주관한 모바일 신분증 안면인식 적합성 평과를 통과했습니다. 금융사 뿐 아니라 지난 7월 모바일 신분증 서비스를 개시한 민간 개방 기업 중에서도 자체 기술로 모바일 신분증 안면인식 적합성 평가를 통과한 곳은 카카오뱅크가 유일합니다[1]. 카카오뱅크는 연구소에서 개발한 자체 안면 인식 기술력을 바탕으로 향후 모바일 신분증 서비스를 보다 고도화하며 안정성 또한 강화할 예정입니다.
안면인식 적합성 평가란 무엇인가?
TTA 인증 받은 모바일 신분증 안면인식 모델 개발기
2025/12/10
서비스


if(kakao)25에서 소개한 카카오뱅크의 프롬프트 어택 탐지 기술
이프카카오는 카카오 그룹의 기술 비전과 연구 성과를 공유하는 연례 행사로, 한 해 동안 집중해 온 기술적 도전과 성과를 개발자 커뮤니티와 함께 나누는 자리입니다. 올해 행사에서는 카카오뱅크 내에서 금융기술연구소가 단독으로 발표 세션에 참여하여, ‘기술 너머의 가능성’이라는 주제 아래 프롬프트 어택(Prompt Attack) 탐지 모델 개발기를 소개했습니다.
Prompt Attack에 대항하는 공든 요새 쌓기 : lab.fortress
2025/11/17
논문




첫인상을 새롭게, 금융기술연구소 디자인 리브랜딩
2025/07/23
디자인


Contents
•
EMNLP & NeurIPS 2024, 그리고 우리의 연구
•
[EMNLP 2024] 한국어 LLM 기반 스미싱 탐지 연구
•
[NeurIPS 2024] LLM 기반 금융 테이블 데이터 생성 연구
•
종합 및 향후 과제
EMNLP & NeurIPS 2024, 그리고 우리의 연구
2024년은 인공지능 및 자연어처리 분야에서 혁신적인 연구가 쏟아진 한 해였습니다. 특히 EMNLP와 NeurIPS는 전 세계 연구자들이 최신 기술과 아이디어를 공유하는 대표적인 학회로, 금융 산업에서의 AI 활용 가능성 역시 한층 넓어진 것을 확인할 수 있었습니다.
카카오뱅크 금융기술연구소는 2024년 11월과 12월에 진행된 EMNLP와 NeurIPS 학회에 직접 참가하여, 연구 성과를 발표했습니다. 또한, 글로벌 연구 동향을 파악하고 카카오뱅크의 연구 방향을 점검하는 소중한 기회를 가졌습니다. 본 글에서는 논문에서 다룬 기술 내용과 발표 현장 스케치, 그리고 이를 바탕으로 한 우리의 연구 방향에 대해 정리하고자 합니다.
EMNLP & NeurIPS 2024 : 한국어 LLM 기반 스미싱 탐지와 금융 데이터 생성 연구
2025/03/27
논문



금융기술연구소의 새로운 시작, ‘Kuzzle’
금융기술연구소 기술로드쇼, ‘Kuzzle’로 새롭게 시작하다
2025/03/07
행사


Contents
•
SHAP 알고리즘 가속화 필요성
•
XAI 가속화 알고리즘 방법론
•
XAI 가속화 알고리즘 평가지표 선정
•
XAI 가속화 알고리즘 개발
•
실험 결과
SHAP 알고리즘 가속화 필요성
카카오뱅크 금융기술연구소에서는 인공지능 알고리즘을 실제 비즈니스 문제에 활용하기 위해 다양한 R&D 활동을 수행하고 있습니다. 이러한 활동 중 하나로 설명가능 인공지능(eXplainable AI, 이하 XAI)에 대해 여러 차례 소개해드렸습니다. 이번 글에서는 산학협력으로 완성한 XAI 알고리즘 가속화 결과에 대해서 이야기 나누고자 합니다.
XAI 알고리즘 관련 소개글
•
•
AI 규제 동향과 카카오뱅크 AI 거버넌스 2024.05.31
•
카카오뱅크의 AI를 설명하는 방법 2024.07.26
•
AI를 설명하면서 속도도 빠르게 할 순 없을까? SHAP 가속화 이야기 (현재)
AI를 설명하면서 속도도 빠르게 할 순 없을까? SHAP 가속화 이야기
2024/12/27
논문

•
본 글의 일부는 <카카오 Tech Ethics> “더 안전한 금융거래를 지원하는 ‘AI 스미싱 문자 확인’ 서비스”에도 같이 발행되었습니다. 인용된 이미지의 저작권과 출처는 <카카오 Tech Ethics>입니다.

스미싱(Smishing)은 휴대폰 문자메시지(SMS)나 SNS로 가족이나 지인, 정부 기관을 사칭해 개인정보를 탈취해 2차 피해를 입히는 범죄입니다. 규제 당국의 자료에 따르면 스팸 메시지 건수는 상반기 대비 2배 가량 증가했습니다. 경찰청은 최근 2년간 스미싱 피해액이 600억 원 억원에 달할 것으로 전망했습니다. 특히 스미싱은 단순한 개인 정보 유출이나 소액 사기와 달리 불법 대출을 비롯한 금융 사기와도 연관이 많아 카카오뱅크에서는 AI로 이를 예방할 수 있는 방안을 고민해 왔습니다.
더 안전한 금융거래를 지원하는 ‘AI 스미싱 문자 확인’ 서비스
2024/12/09
서비스


매일 같이 새로운 LLM이 공개되는 지금, 우리는 쏟아지는 LLM 속에서 어떻게 나에게 딱 맞는 모델을 찾을 수 있을까요?
또 우리는 어떻게 “말을 잘 한다” 는 기준을 수치화할 수 있을까요?
금융기술연구소가 if(kakaoAI) 2024에서 발표한 카카오뱅크 시선에 맞춘 LLM을 평가 및 검증 능력의 내재화 경험을 공유합니다.
LLM 평가 프레임워크 구축기 : 최적의 LLM을 선택하는 방법, DUO
2024/11/26
신기술

AI로 확장해 나가는 if(kakaoAI) 2024
올해 6회째를 맞는 이프카카오는 카카오 그룹의 기술 비전 공유 행사로, 한 해 동안 역점을 둔 기술 및 연구 개발 성과들을 개발자 커뮤니티에 공개하고 소통하는 장입니다. 특별히 올해는 주제를 AI에 집중시켜 ‘모든 연결을 새롭게’라는 슬로건을 정했으며, 영문 행사명에 AI를 추가하고 장소도 작년 말 완공된 용인 ‘카카오 AI 캠퍼스’에서 개최하게 되었습니다. 금융기술연구소는 카카오뱅크를 대표해 3개 세션 발표를 참여하여 금융 서비스에 LLM을 어떻게 적용하고 개선하고 있는지에 대한 선도적 시도와 상세한 노하우를 전달했습니다.

금융 도메인 LLM 평가 지표 및 방법 / SHAP 가속화 / 스미싱 탐지
금융기술연구소 if(kakaoAI)2024 3개 세션 발표
2024/10/24
행사

•
본 글의 일부는 <카카오 Tech Ethics> ‘카카오뱅크의 AI를 설명하는 방법’에도 같이 발행되었습니다. 인용된 이미지의 저작권과 출처는 <카카오 Tech Ethics>입니다.

AI를 통한 새롭고 안전한 이용자 경험 제공
카카오뱅크의 AI를 설명하는 방법
2024/07/26
연구과제


국내 은행 최초 AI 전용 데이터센터 개소
카카오뱅크는 지난 2월 AI 센터를 개소했습니다. AI 센터(AI Data Center)는 AI 연구개발 만을 위해 별도 설립하는 전용 데이터센터로 구글, 마이크로소프트, 아마존을 비롯한 빅테크들도 최근 조 단위 투자 계획을 밝히고 있습니다. 카카오뱅크는 국내 은행 중에서는 처음으로 자체 AI 전용 연구 장비를 보유하게 되었으며, 엔비디아 최신 GPU ‘H100’을 도입했다는 점이 인프라 측면에서 가장 눈에 띄는 부분입니다. AI 센터 덕분에 신분증 인식, 셀카인증(Selfie Authentication), 신용평가 모형, 이상거래탐지시스템(FDS), AI 고객센터(AICC) 등 카카오뱅크가 진행 중인 다양한 기술개발에 더욱 박차가 가해질 수 있을 것으로 예상됩니다. 금융기술연구소는 많은 자원과 계산량이 필요했던 안면인식 기술 개발에 H100을 바로 적용해보면서 체험한 개선 효과를 소개하고자 합니다.
안면인식 기술 개발로 살펴본 H100 도입 효과
2024/07/25
신기술


금융권 AI 도입 가속화와 규제 대응
모든 산업에서 AI 도입이 가속화되고 있는 가운데, 범국가적 규제 준수와 기술적으로 안정성과 투명성을 확보하는 문제도 같이 중요해지고 있습니다. 금융 산업에서는 고객 응대와 간단한 상담을 해주는 AI 행원이 시중은행 지점에 등장했고, 증권사는 해외주식 정보를 실시간으로 요약해 주는 서비스나 버추얼 애널리스트가 투자 상품을 추천해 주는 서비스를 앱에 탑재했습니다. 이러한 신기술 도입은 정확하고 책임질 수 있는 정보 전달과 고객 보호를 충분히 고려했는지에 대한 법률 검토가 필요하며, 기존 법체계가 새로운 사회 현상과 위험 요소를 온전히 반영하지 못했을 경우 새로운 입법이 이뤄지게 됩니다.
올해 3월 유럽연합 본회의를 최종 통과한 AI법(EU Artificial Intelligence Act)은 AI가 초래할 수 있는 위험을 광범위하게 검토하고 위법 사항에 강도 높은 제재를 채택했다는 점에서 주목을 받았습니다. 유럽연합의 입법 방향성은 익히 알려져 있었고 개별 기업마다 AI 윤리 측면에서 고객 권리 보호와 서비스 안정성 확보를 자율적으로 준비해 왔으나, AI법 시행으로 강제성이 생긴 만큼 더 탄탄한 대비가 필요해진 것입니다. 카카오뱅크도 지난 1월 ‘오늘의 mini 일기' 서비스 출시하고 AI실 조직을 신설하면서 사내외 서비스들과 AI 접목을 전방위적으로 검토하고 있기에, 국내외 AI 규제 동향을 살펴보고 관련해서 대응해 온 과정을 소개해 보고자 합니다.
AI 규제 동향과 카카오뱅크 AI 거버넌스
2024/05/31
연구과제


국내 금융사 최초 생성형 AI 활용
카카오뱅크는 지난 1월 29일부터 한 달 여 간 결제 내역 기반으로 AI가 나만의 일기를 만들어주는 ‘오늘의 mini 일기’ 이벤트를 진행했습니다. 이번 이벤트는 금융기술연구소가 서비스 기획 및 개발 부서와 오랫동안 협업해서 준비해 온 것으로, 생성형 AI가 쓰인 대고객 금융 서비스로는 국내 첫 사례입니다. 연구소는 작년에 화두가 된 LLM 서비스를 금융 상품에 활용할 수 있는 시나리오를 찾기 위해 연초부터 내부 워크숍을 여러 차례 운영하고 고민을 거듭했습니다. 하루 요약 일기 생성 서비스는 당시에 나왔던 아이디어들 중 하나로, 처음에는 친근한 이미지를 곁들이거나 금융 특화형 SNS까지 다양한 기능을 연결해 보자는 의견도 있었습니다.
본격적인 서비스 개발은 Elena, Vivaan, Luna가 체크카드 결제 내역을 기반으로 일기를 생성하는 PoC를 사내에 공개한 후, 서비스 기획 부서에서 흥미롭게 보고 이벤트에 적용해 볼 것을 제안해 주면서 시작되었습니다. GPT 계열 언어모델이 텍스트로만 된 결제 내역을 정확히 변환해 주었고, 2~3단계 질문 만으로 이모티콘까지 포함된 센스 있는 표현을 인스타그램 스타일로 자연스럽게 생성해 주는 결과가 이목을 끌었습니다. 시작은 호기로웠지만 카카오뱅크의 생성형 AI 기반 첫 번째 서비스가 탄생하기까지는 신기술 검증부터 시나리오 기획과 최적화까지 많은 요소를 고려하고 확인하는 절차를 거쳐야 했고 서버, 클라우드, 모바일 등 여러 개발 부서 도움이 필요했습니다.
따뜻한 AI가 응원해 주는 나의 하루, '오늘의 mini 일기' 서비스 준비 과정
2024/03/08
서비스



대내외 협업 취지
금융기술연구소 3주년 기념 주요 성과 리뷰 3편 협력과 도전
2024/02/19
행사



연구 과제 현황
금융기술연구소 3주년 기념 주요 성과 리뷰 2편 논문•특허
2024/01/31
논문
특허



행사 소개 및 컨셉
금융기술연구소 3주년 기념 주요 성과 리뷰 1편 행사 소개
2024/01/18
행사


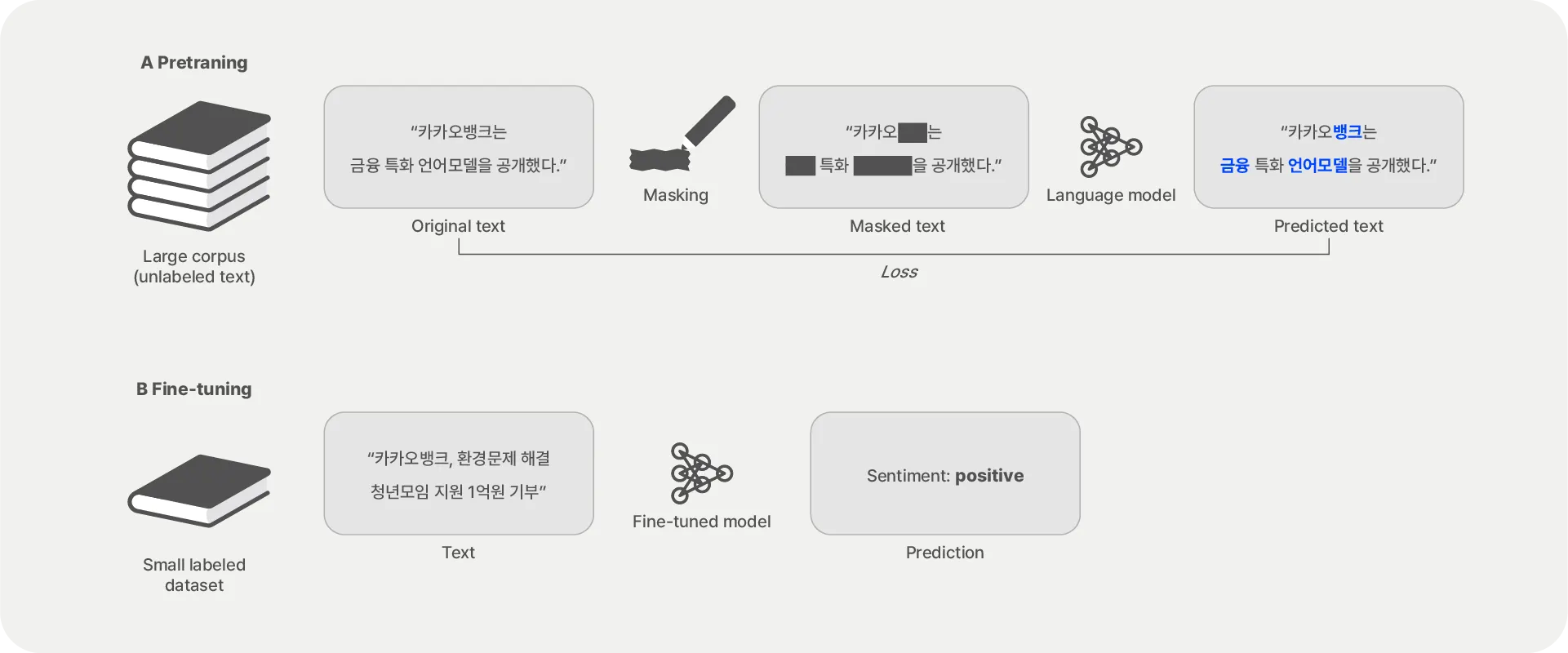
카카오뱅크의 금융특화 언어모델 KF-DeBERTa 개발기
2023/12/20
오픈소스
논문
카카오뱅크 금융기술연구소
Financial Tech Lab