


국내 은행 최초 AI 전용 데이터센터 개소
카카오뱅크는 지난 2월 AI 센터를 개소했습니다. AI 센터(AI Data Center)는 AI 연구개발 만을 위해 별도 설립하는 전용 데이터센터로 구글, 마이크로소프트, 아마존을 비롯한 빅테크들도 최근 조 단위 투자 계획을 밝히고 있습니다. 카카오뱅크는 국내 은행 중에서는 처음으로 자체 AI 전용 연구 장비를 보유하게 되었으며, 엔비디아 최신 GPU ‘H100’을 도입했다는 점이 인프라 측면에서 가장 눈에 띄는 부분입니다. AI 센터 덕분에 신분증 인식, 셀카인증(Selfie Authentication), 신용평가 모형, 이상거래탐지시스템(FDS), AI 고객센터(AICC) 등 카카오뱅크가 진행 중인 다양한 기술개발에 더욱 박차가 가해질 수 있을 것으로 예상됩니다. 금융기술연구소는 많은 자원과 계산량이 필요했던 안면인식 기술 개발에 H100을 바로 적용해보면서 체험한 개선 효과를 소개하고자 합니다.


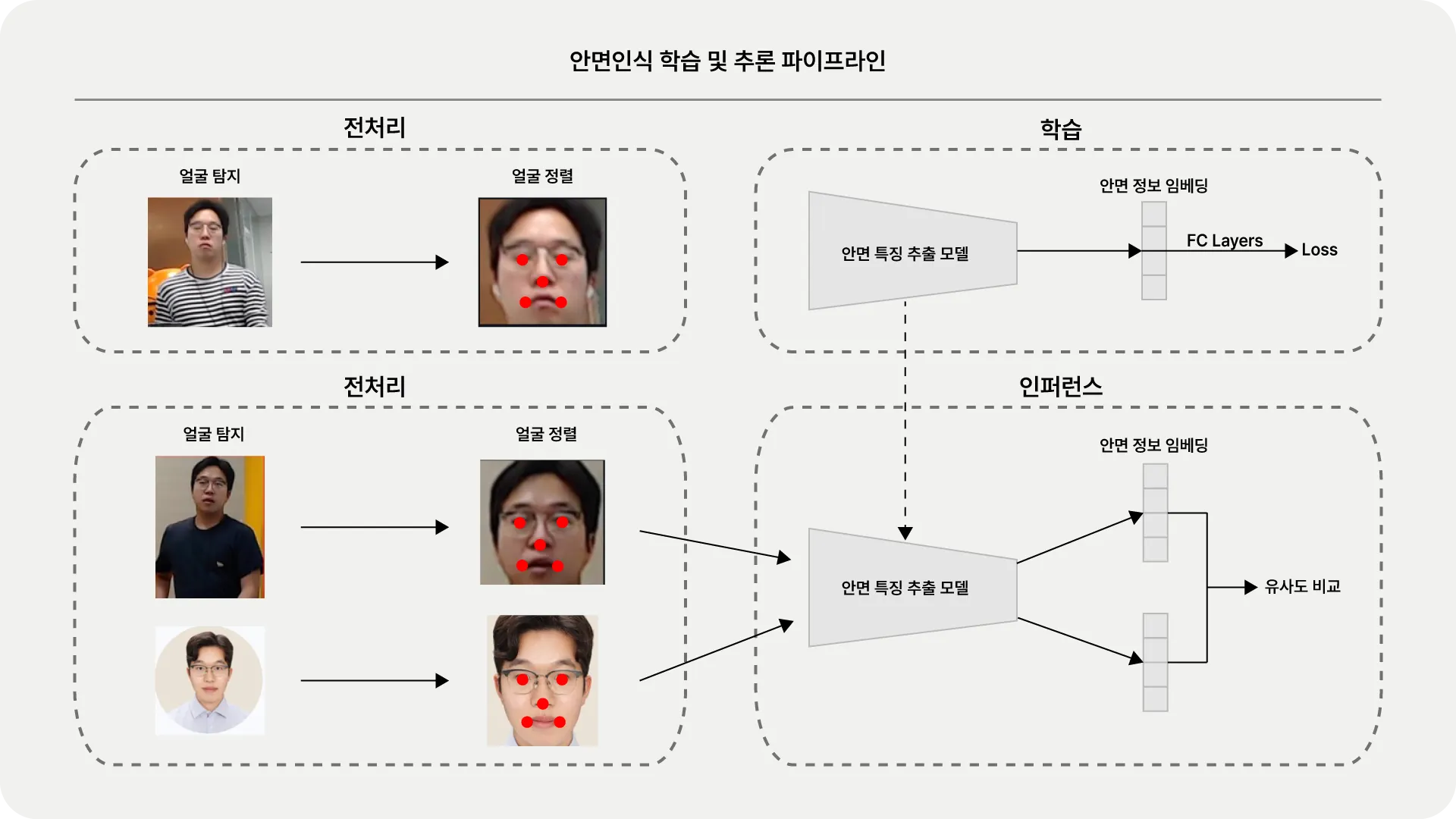
안면인식 학습 및 추론 과정
안면인식 과정은 크게 전처리와 안면 특징 추출 2단계로 나누어져 있습니다. 전처리 단계에서는 이미지 내에서 얼굴을 탐지(Detection)하고, 눈, 코, 입 등 특징 좌표를 동일한 좌표로 위치시키는 정렬(Alignment) 작업을 수행합니다. 이후 안면 특징 추출 단계에서 앞서 정렬된 안면 이미지를 바탕으로 개개인을 특성을 ‘식별’하는 분류 모델을 만듭니다. 이때 모델은 개개인을 잘 분류하기보다, 안면 특징 정보를 잘 추출해 낼 수 있는 임베딩(Embedding) 생성을 목표로 합니다. 실제 서비스 단계에서는 학습 단계에서 없었던 새로운 사람이 등장할 수 있기 때문에, 새로운 사람에 대해서도 안면 특징을 잘 표현할 수 있도록 임베딩을 만들어내는 것이 중요합니다. 이렇게 만들어진 두 임베딩을 비교해서 같은 사람인지 다른 사람인지를 판별합니다.
안면 특징 추출에 영향을 주는 학습 데이터와 연산량
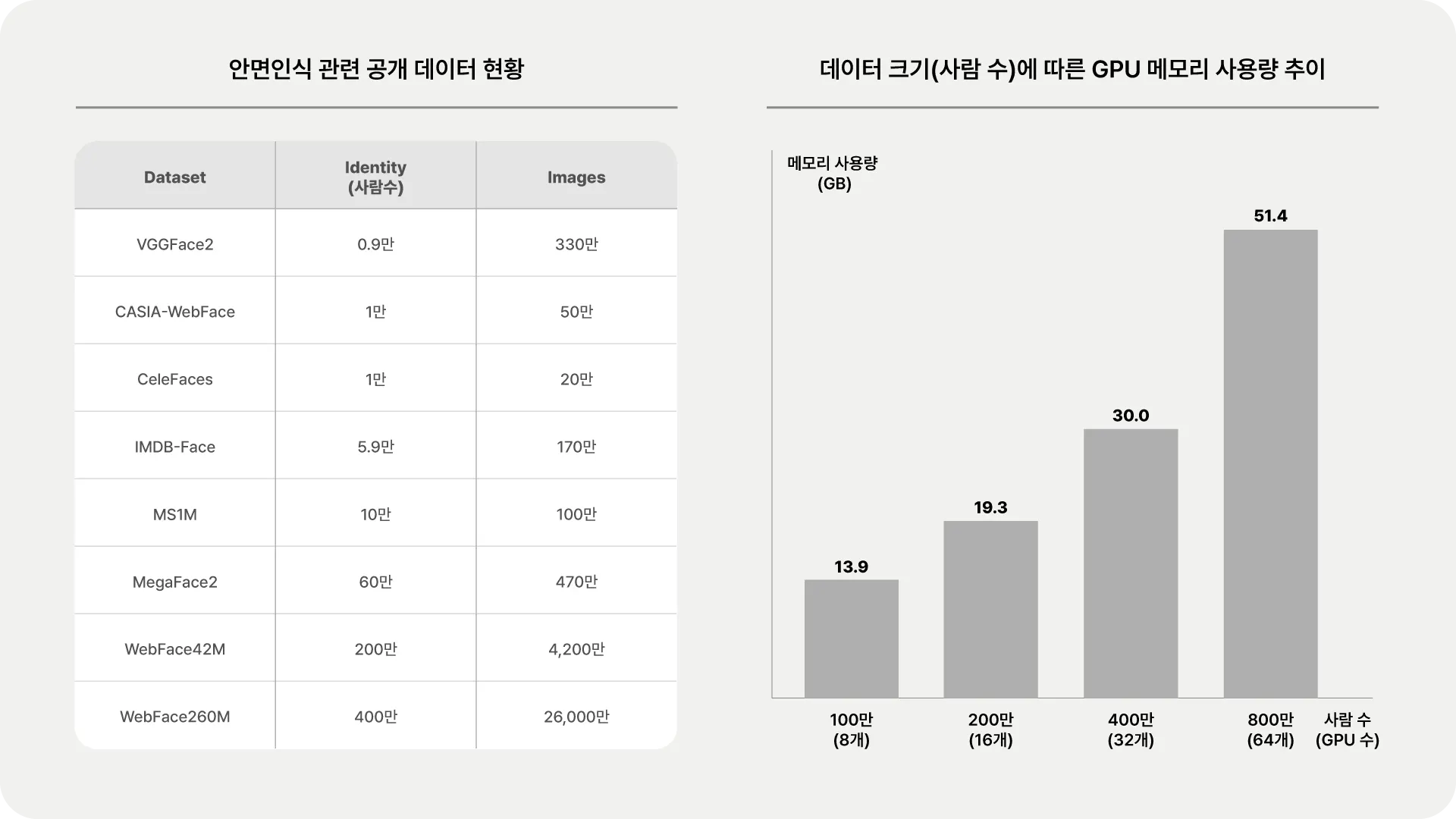
임베딩을 정교하게 만들기 위해서는 학습에 사용되는 데이터 양이 무엇보다도 중요합니다. 대부분 딥러닝 모델은 데이터가 많아질수록 성능이 상승하는 경향이 있습니다. 안면 인식은 개별 얼굴 특징을 식별해야 한다는 측면에서 더 난이도가 있어서 데이터 중요성이 보다 부각됩니다. 관련 연구(2, 3)에서도 데이터 크기가 커질수록 성능이 상승함을 보여주고 있고, 같은 추세로 최근 공개되는 안면 관련 공개 데이터 크기가 점점 커지고 있습니다. 가장 큰 규모로 최근 공개된 WebFace260M는 사람 수(Identity)만 400만 명, 이미지는 2억 6000만 장으로 TB 단위에 육박합니다.
이렇게 많은 학습 데이터를 처리하기 위해서는 큰 용량의 GPU 메모리가 필요하며, 특히 사람 수가 늘어날수록 메모리 사용량이 비례해서 증가합니다. 보통 GPU 메모리 사용량은 모델 크기와 배치 크기에 영향을 받는다고 알려져 있는데, 안면인식에서는 사람 수만큼 분류(Classification) 연산을 진행하기 때문에 숫자가 큰 영향을 줍니다. 예를 들어 400만 명 데이터로 학습한다고 하면, 400만 명 각각을 구분하고 분류하는 연산을 수행합니다. 이는 400만 개 가중치(Weight)를 가지고 있다는 뜻이며 모델 크기와 배치 크기를 더한 메모리 사용량을 환산하면 약 30GB를 차지합니다. 일반 PC에서 주로 사용하는 GPU RTX 3090은 메모리 용량이 24GB에 불과해서 애초에 학습을 시작할 수 조차 없는 수준입니다.
H100 도입에 따른 효과 분석
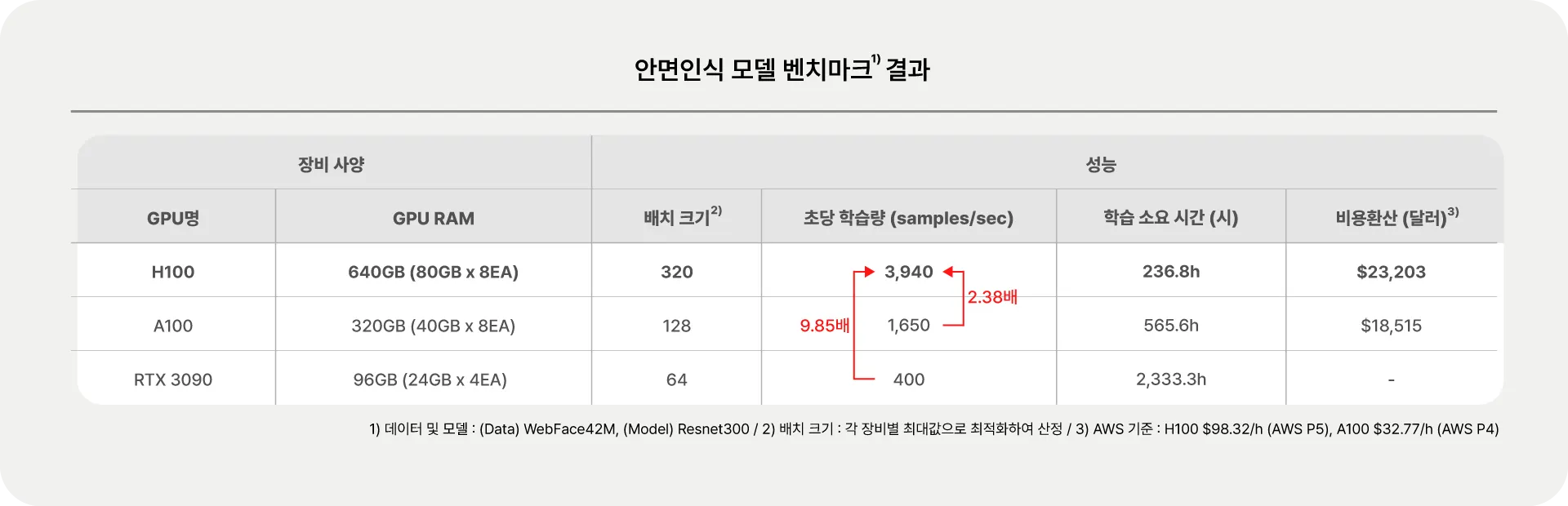
금번 AI 센터에 도입된 H100은 한층 향상된 속도와 메모리로 안면인식 모델 개발에 큰 역할을 하고 있습니다. 개선 효과를 수치로 비교하기 위해 금융기술연구소에 있는 RTX 3090(24GB x 4EA)과 연구소 서버에서 사용하는 A100(40G x 8EA)으로 벤치마크를 수행했습니다.(학습 데이터 WebFace42M, 학습 모델 ResNet) 가장 먼저 눈에 띄는 효과는 바로 학습 속도로, A100 대비 초당 2.38배, RTX 3090 대비 9.85배 이상 차이를 보입니다. WebFace42M 총 학습 소요 시간으로 환산하면 그 효과가 더욱 체감되는데, RTX 3090이 100일(약 2,333시간) 가까이 소요되는 것에 반해 H100은 10여 일 만에 학습 결과를 확인할 수 있습니다. 일반적으로 모델 학습에 실험이 여러 번 수반된다는 점을 감안할 때 새로운 모델 한 개 개발에 시간을 몇십배 절약할 수 있습니다.
두 번째는 기존에 학습하지 못한 대규모 데이터와 모델을 학습할 수 있다는 점입니다. 이번 벤치마크에서는 세 장비 모두 학습이 가능한 수준인 데이터와 모델을 선택했지만, H100 환경에서는 더 큰 데이터와 모델을 사용하더라도 문제없이 돌아가는 것을 확인할 수 있었습니다. 뿐만 아니라 배치 크기 또한 키울 수 있어 추가적인 학습 소요시간 단축 및 정확도 수렴 속도를 보다 빠르게 할 수 있다는 장점이 있었습니다.
이뿐만 아니라 전력 사용량 또한 개선될 것으로 예상됩니다. H100과 RTX3090 각각의 최대 소비전력은 700W, 350W로 단순 비교하면 H100이 2배 높습니다. 벤치마크 환경에 사용된 전체 GPU 개수를 반영하여 계산하면 H100이 5,600W(8개), RTX 3090이 1,400W(4개)로 단위 시간당 전력 소비량은 H100이 4배 높습니다. 하지만 이번 실험에서 학습 소요 시간이 대략 1/10로 줄어들어, 총 사용 전력량으로 환산 시(최대 소비전력 x 학습 소요 시간) 대략 60% 정도 전력 소모량이 절감되는 것을 확인할 수 있습니다.
결과적으로 H100 도입을 통해 기존에 할 수 없는 더 많은 시도를 할 수 있으며, 생산성 또한 획기적으로 향상할 수 있음을 보였습니다. 카카오뱅크에서는 HGX 이외에도 DGX와 InfiniBand 구성까지 각 팀과 프로젝트 환경에 맞춘 여러 형태의 GPU 장비들을 운영하며 효율화를 추구하고 있습니다. InfiniBand를 적용하면 일반 네트워크 환경보다 절반 가까이 연산 소요 시간이 단축되었고, 4대 이상 연동했을 때 부터 거대 모델의 계산량 분산 효과가 확연하게 나타났습니다. 이를 바탕으로 다양한 연구 분야에서 얻은 기술 개발 성과는 다음 기회에 정리해 보도록 하겠습니다.


카카오뱅크 금융기술연구소
Financial Tech Lab