


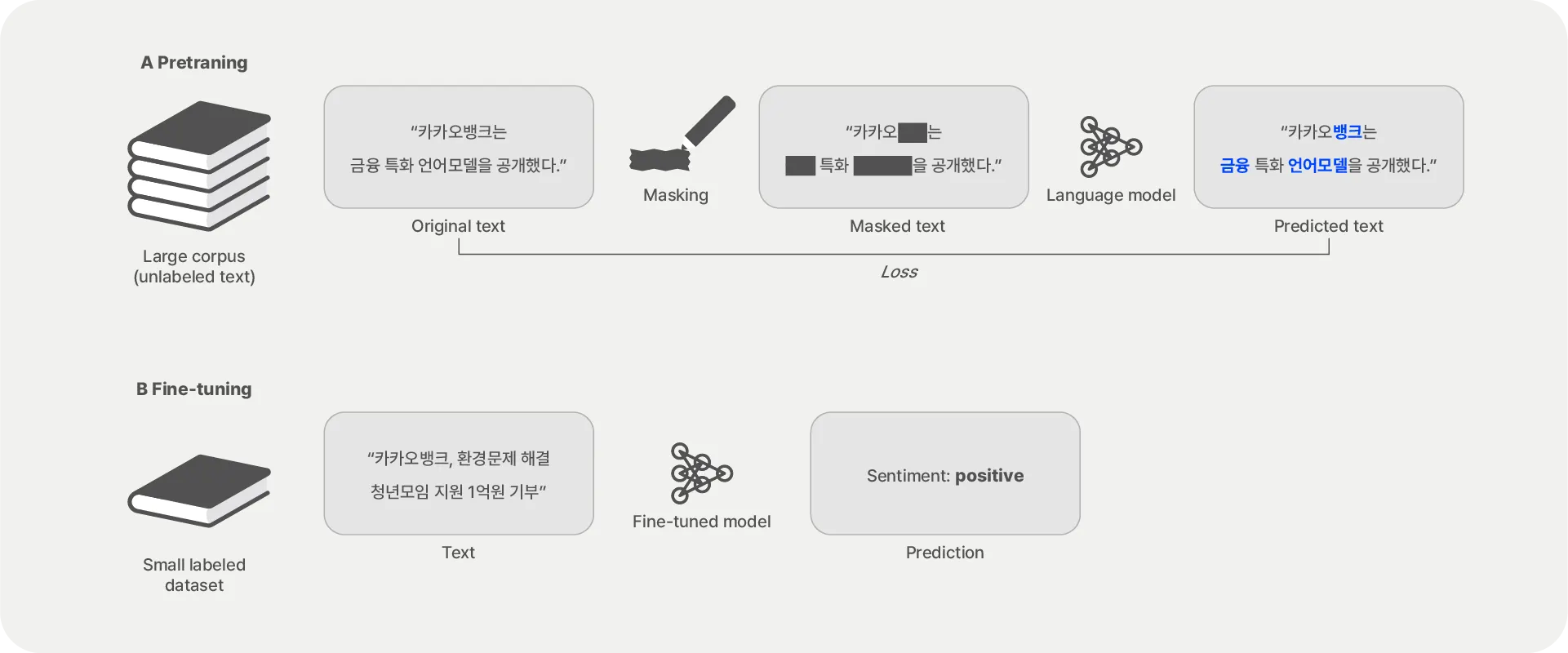
연구 배경
최근, 대규모 언어모델(Large Language Models, LLM) 등장으로 자연어처리 기술이 비약적으로 발전했으나 금융 용어 및 도메인 지식에 전문화된 언어모델은 부족해서 은행을 비롯한 금융기관에서 최신 언어모델을 쓰기에 아직 어려움이 많습니다. 사전학습 언어모델(Pre-trained Language Model, PLM)은 범용 언어모델보다 특정 도메인 이해도를 집중적으로 높이기 위한 방식입니다.
카카오뱅크는 기업 금융 정보 전문 기업인 에프엔가이드(FnGuide)와 함께 1년 여 동안 고품질의 한국어 금융 학습 데이터를 구축하고, 이 학습 데이터에 최적화시킨 KF-DeBERTa 언어모델을 국내 금융사 최초로 GitHub와 Hugging Face를 통해 대중에게 공개합니다. KF-DeBERTa는 학술적 공로를 인정 받아 지난 10월 35회 한글 및 한국어 정보처리 학술대회(HCLT 2023)에서 우수상을 수상하기도 했습니다. 모델 이름의 KF는 ‘Korean Finance’와 ‘Kakaobank + FnGuide’를 의미합니다.
문제 정의
일반 언어모델들은 아무리 모델이 크고 학습 데이터가 방대하더라도 범용 말뭉치(General corpus) 기반이라 높은 전문지식(Domain knowledge)이 필요한 분야에서는 한계를 보이는 경향이 있습니다. 그나마 공개된 데이터가 충분한 분야는 준수한 성능을 보이나 금융처럼 전문용어 사용이 많은 분야는 양질의 한국어 데이터 자체가 부족합니다. 특히 금융 산업은 법률 규제로 인해 자체 보유한 데이터를 외부에 공개하기 어려운 보수적 분위기가 강하며, 금융 관련 서비스에 언어모델이 쓰이려면 다음 3가지 요소가 보완되어야 합니다.

금융관련 서비스에 언어모델이 쓰이기 위해 보완되어야 할 3요소
•
일반적으로 사용되지 않는 금융 용어에 대한 이해
•
금융상품명 등 고유명사에 대한 이해
•
문서 내 수치 및 값에 대한 이해(Numerical reasoning)
한가지 전문 분야에 특화시키는 언어 모델은 과학기술 Galactica (Meta), 의료 Med-PaLM (Google), 법률 Legal-BERT (Athens University), 임상기록 GatorTron (Nvidia, University of Florida) 등 여러가지가 시도되고 있습니다. 금융 분야는 BloombergGPT (Bloomberg)와 FinBERT (Prosus)가 유명합니다. 주로 영어권 언어모델이며, 국내에서는 2021년 KB국민은행이 KB-ALBERT를 공개했지만 모델 파일은 별도 허가를 얻어야 받을 수 있습니다.
자연어처리 성능이 뛰어나다고 해도 무조건 거대한 언어모델을 활용하는 것은 개발 투자와 서비스 운영 비용 관점에서 부담스럽기도 합니다. 다양한 여건들을 고려해, 카카오뱅크와 에프엔가이드는 양방향(Bi-directional) 구조로 문맥을 양방향으로 이해하고 위치정보를 포함한 Disentangled Attention이 도입된 DeBERTa을 토대로 자체 금융특화 언어모델을 개발했습니다.
주요 특징
Transformer와 MLM (Masked Language Modeling) task가 핵심인 BERT 언어모델은 단방향(Uni-directional) 구조인 GPT 언어모델에 비해 자연어 문맥 이해 성능에 더 우수함을 보이고 있습니다.(대신 GPT 계열은 자연어 생성에 강점) 2018년 처음 발표된 이후 더 많은 데이터를 소화하기 위한 절차 변형과 새로운 학습 기법 도입, 모델 크기 경량화, 임베딩 표현 변경 등 개선이 지속적으로 이뤄지고 있습니다.
•
RoBERTa (2019) : batch 크기와 학습 step 확장, NSP (Next Sentence Prediction) task 제거
•
ALBERT (2019) : 경량화, NSP 대신 SOP (Sentence Order Prediction) task 사용
•
ELECTRA (2019) : MLM task의 계산 비효율성 개선한 RTD (Replaced Token Detection) task 사용
•
DeBERTa (2020) : Attention 매커니즘에 상대적 위치 정보 추가, content와 position 2가지 임베딩 사용
카카오뱅크와 에프엔가이드는 DeBERTa를 기반으로 ‘금융 도메인 뿐만 아니라 범용 도메인에서도 좋은 성능을 보이는 자체 언어모델’을 목표로 새로운 말뭉치 학습 데이터를 수집했습니다. 에프엔가이드는 20년 넘게 축적해온 데이터를 바탕으로 잘 정제된 금융 도메인 데이터를 제공하는 역할을 수행했고, 카카오뱅크는 범용 도메인 말뭉치 수집 및 언어모델 최적화를 담당했습니다.
그 결과 현재 공개된 양방향 언어모델들과 비교했을 때 가장 많은 학습 데이터를 확보했으며, 언어모델 사전학습(Pretraining)을 통해 성능을 끌어올렸습니다. 사전학습에 사용된 말뭉치는 문장단위 분할, HTML 태그 및 잘못된 문자 제거, 출처 정보 제거, 비한글 문장 제거, 숫자 비중 높은 문장 제거, 짧은 문장 제거(10 음절 이하) 등 전처리를 수행했습니다. 미세조정(Fine-tuing)을 위한 한국어 금융 데이터도 전문 금융 리포트와 관련 소식들 재가공해서 새로운 레이블링 작업과 기계 번역을 거쳐 완성했습니다.
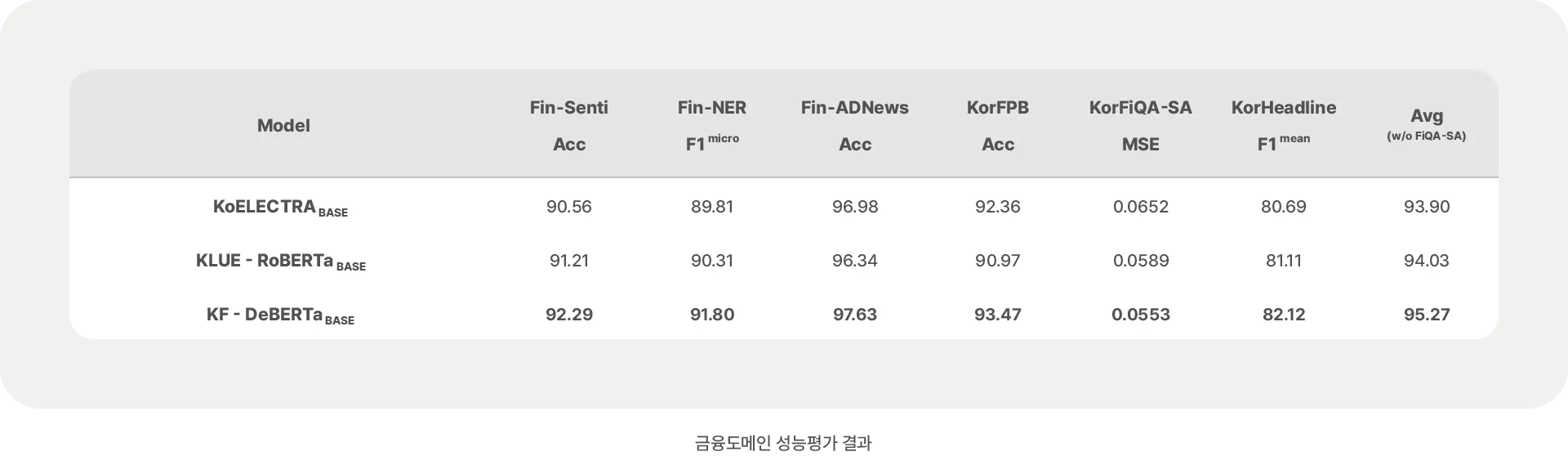
성능 비교
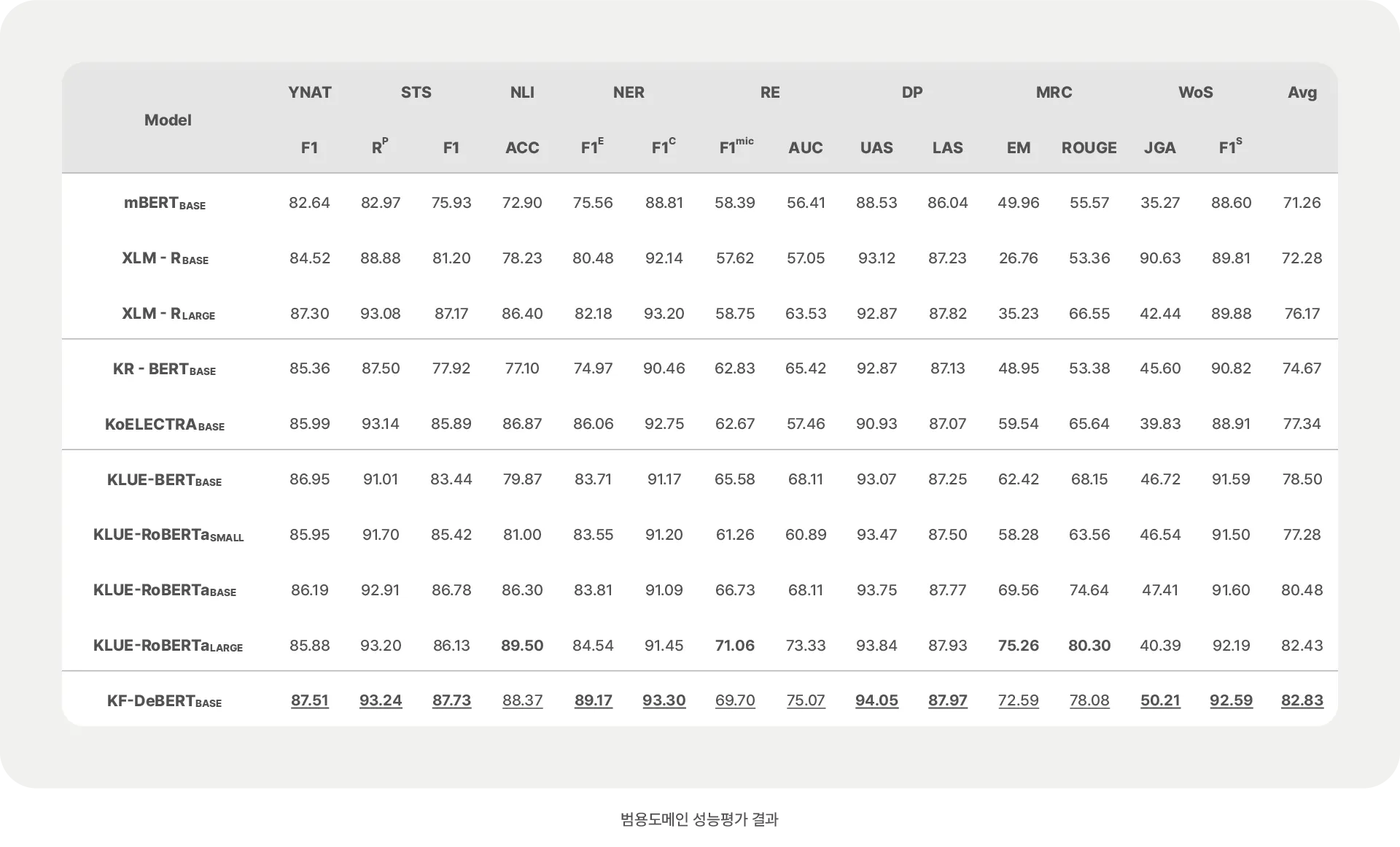
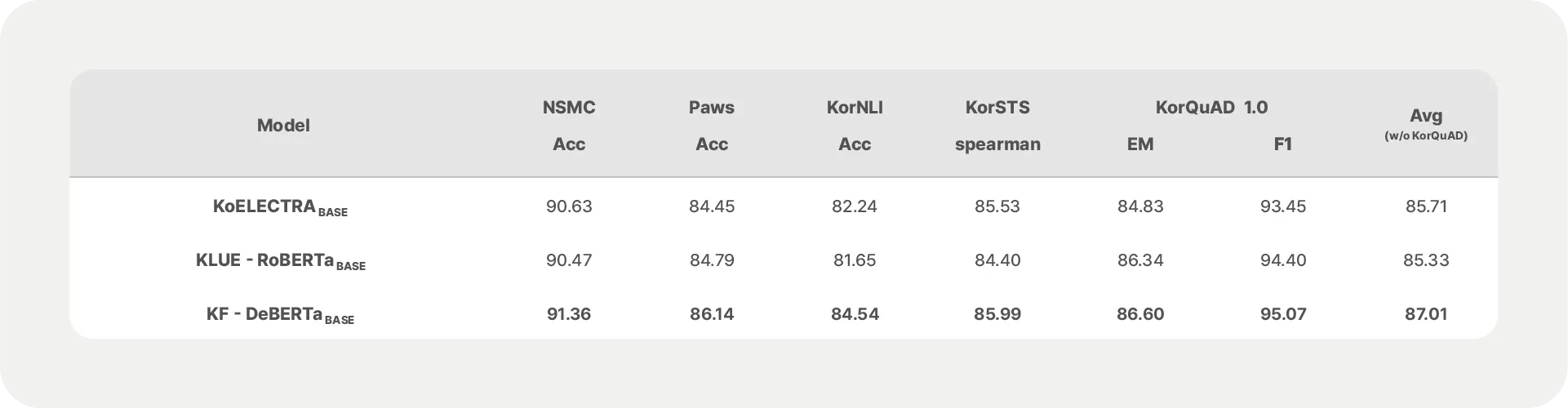
성능 비교는 국내 유수 대학과 기업들이 공동으로 개발하여 현재 한국어 언어 이해 모델 표준으로 인정 받고 있는 KLUE-RoBERTa, 국내 오픈소스 그룹에서 ELECTRA 언어모델을 34 GB 분량의 한국어 데이터로 재학습시켜서 공개한 KoELECTRA 등 2가지 언어모델과 수행했습니다. 금융 도메인 성능 평가의 신뢰성 향상을 위해 Financial PhraseBank, FiQA-SA, Headline 영어 데이터를 한글로 번역하여 평가에 추가로 사용했습니다.
KF-DeBERTa는 모든 금융 도메인 평가에서 KLUE-RoBERTa 보다 평균 1% 이상 우수한 성능을 나타냈습니다. 범용 도메인 평가에서 같은 크기의 모델인 KLUE-RoBERTa base 보다 평균 2% 이상 우위였고, 더 큰 모델인 large와 비교했을 때 일부 뒤지는 영역이 있지만 평균 0.4% 이상 나은 결과를 보여주었습니다.
•
Fin-Senti : 금융도메인 감성분류 데이터셋 (애널리스트 금융 리포트 및 공시 자료, 에프엔가이드 DB)
•
FIn-NER : 금융도메인 개체명인식 데이터셋 (애널리스트 금융 리포트 및 공시 자료, 에프엔가이드 DB)
•
Fin-ADNews : 금융도메인 광고 분류 데이터셋 (애널리스트 금융 리포트 및 공시 자료, 에프엔가이드 DB)
•
KorFPB : 금융도메인 감성분류 데이터셋 (Financial PhraseBank 번역 데이터)
•
KorFiQA-SA : 금융도메인 감성분류 데이터셋 (FiQA-SA 번역 데이터)
•
KorHeadline : 뉴스가 원자재 시장에 미치는 영향 분류 (Headline 번역 데이터)
•
YNAT : 뉴스 카테고리 분류
•
STS : 텍스트 유사도 측정
•
NLI : 텍스트 관계도 분석
•
NER : 개체명 인식
•
RE : 속성끼리 의미 관계 식별
•
DP : 단어 간의 관계정보 식별
•
MRC : 주어진 구절에서 질문에 대한 답변추출
•
WoS : 대화 시스템에서 에이전트의 대화 상태를 추론
•
NSMC : 영화댓글 감성분석
•
Paws : 문장간 의미 분석
•
NorNLI : 텍스트 관계도 분석
•
KorSTS : 텍스트 유사도 측정
•
KorQuAD : 주어진 구절에서 질문에 대한 답변 추출
시사점
이번에 공개한 KF-DeBERTa는 자연어이해 작업에서 기존 사전학습 언어모델보다 금융 및 범용 도메인에서 월등한 성능을 보여주었습니다. 금융특화 언어모델은 앞으로 카카오뱅크 각종 내부 서비스 성능 개선에 쓰일 수 있을 것으로 예상됩니다. 내부 데이터베이스 금융 키워드 추출, 금융 문서 내 개체명 인식, 문맥상 사실 관계 검증, 의미론 검색, QA 시스템 등이 대표적입니다. 내부 고객센터 KMS 검색엔진에는 KF-DeBERTa를 기반으로 미세조정된 임베딩 모델과 키워드 추출 모델이 이미 적용되어 과거보다 훨씬 더 질의에 적합한 결과를 뽑아주고 있습니다. 이외에도 개인정보 탐지, 자금세탁방지 솔루션 등에 적용을 시도하고 있으며 일반 고객용 서비스까지 언어모델이 반영되는 날도 그리 멀지 않았다고 기대해 봅니다.
사용 방법
•
Hugging Face: https://huggingface.co/kakaobank/kf-deberta-base
•
MIT 라이선스: 저작권 표기 시 자유로운 배포 가능, 책임 비보증
참고 자료
•
DeBERTa: Decoding-enhanced BERT with Disentangled Attention, He et al. (Microsoft), ICLR 2021

카카오뱅크 금융기술연구소
Financial Tech Lab