


연구배경
금융권에서 AI 기반 고객 서비스가 확대되면서 정확한 정보 검색(Information Retrieval; IR)의 중요성이 커지고 있습니다. 특히 은행은 상품 안내부터 약관 설명까지 다양한 고객 문의를 처리하기 위해 정교한 IR 시스템이 필요합니다. 하지만 기존 금융 정보 검색 벤치마크는 몇 가지 한계가 있었습니다.
•
주로 재무제표가 뉴스 분석에 집중되어 있어 실제 은행 업무에 적용하기 어려움
•
여러 문서를 참조해야 하는 복잡한 질의가 부족
•
한국어 금융 도메인 데이터셋 부재
•
실제 고객 데이터 사용의 법적 제약
이러한 문제를 해결하기 위해 LLM 기반 2단계 쿼리 생성 파이프라인을 개발했습니다. LLM을 활용한 ‘단일 문서 쿼리 생성’과, 실제 고객 문의 패턴을 분석하여 도출한 3가지 IR 시나리오(Topic-based Merging, Context Deepening, Comparing & Contrasting) 기반의 ‘다중 문서 쿼리 생성’을 통해 더 복잡한 난이도의 쿼리를 확보했습니다. 또한 기존 자동 평가 방식의 한계를 극복하기 위해 Reasoning 기반의 강화된 평가 방법을 도입하여 사람의 평가와의 일관성을 개선했습니다.
주요 연구 내용
1. 쿼리 생성 파이프라인
파이프라인은 단일 문서 쿼리 생성과 다중 문서 쿼리 생성의 두 단계로 구성됩니다.
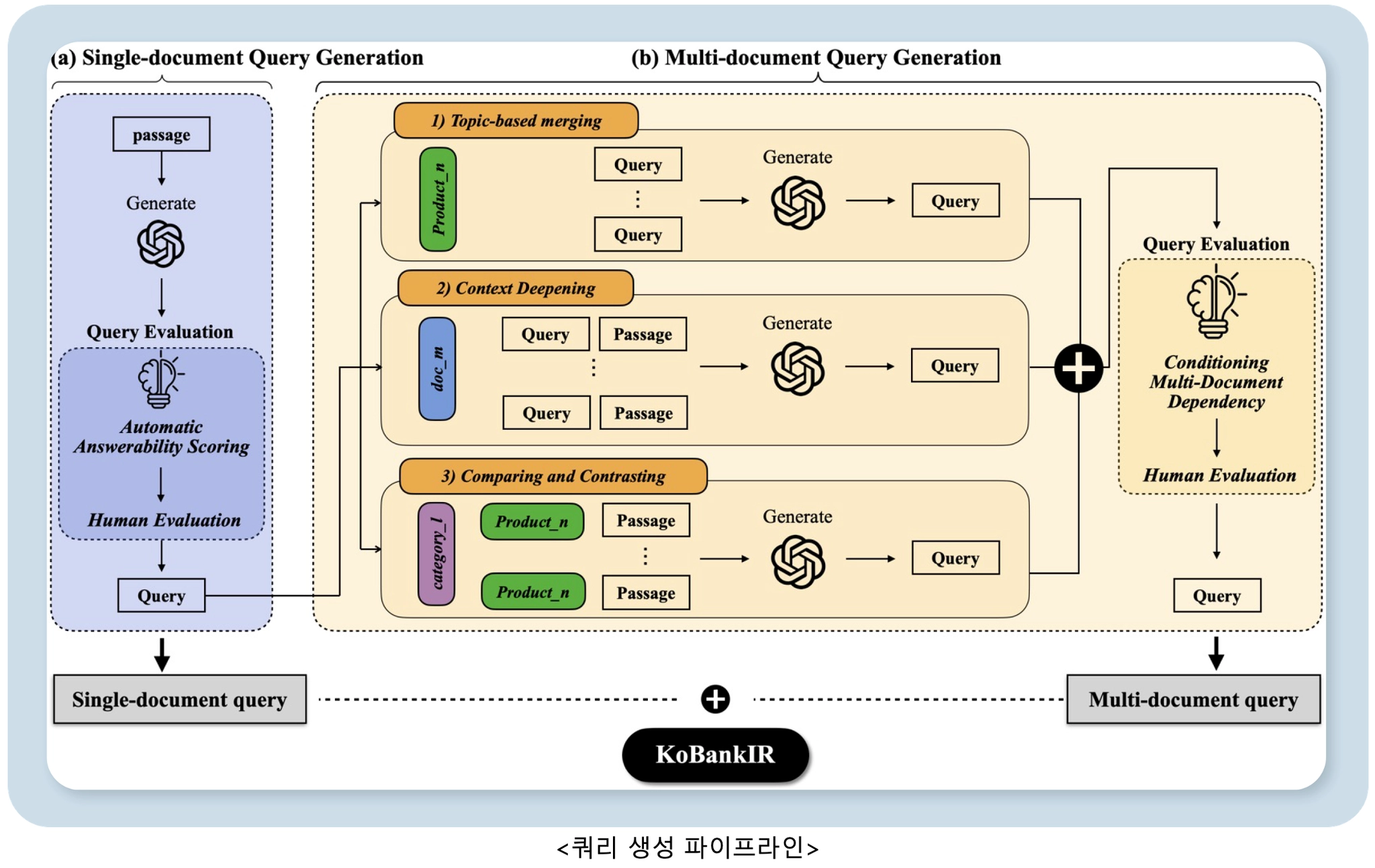
 단일 문서 쿼리 생성
단일 문서 쿼리 생성각 문서 passage에서 GPT-4o를 활용해 쿼리를 생성했습니다. 이때, 상품명 등 메타데이터를 포함하여 실제 고객 문의 상황을 시뮬레이션하여 생성하고, 쿼리에 상응하는 문서를 기반으로 답변이 가능한지를 평가하는 ‘답변 가능성 평가’를 통해 고품질 쿼리만을 선별했습니다.
다중 문서 쿼리 생성실제 서비스 환경에서 고객들은 하나의 문서만으로 답변이 불가능한 질문들을 자주하곤 합니다. 이에, 고객 문의 데이터를 기반으로 여러 문서를 함께 참조해야 하는 IR 패턴을 분석하여 3개의 주요 시나리오를 도출하였고 각각에 상응하는 다중 문서 쿼리 생성 방안을 설계했습니다. 도출한 주요 IR 시나리오는 다음과 같습니다.
•
Topic-based merging : 동일 상품 관련 쿼리들을 자연스럽게 결합
•
Context deepening : 여러 단계의 추론이 필요한 심화 질문 생성
•
Comparing&contrasting : 상품 간 비교·대조 질문 생성
예시는 다음과 같습니다.

2. 답변가능성 평가 방법 개선
기존의 평가방식인 G-EVAL은 QGEval 벤치마크에서 다른 평가 방법들 대비 사람 평가와의 일관성이 가장 우수한 것으로 알려져 있습니다[1]. 하지만, 사람 평가와의 Pearson 상관계수는 0.36에 불과했습니다. 이는 금융 도메인의 복잡한 답변가능성 판단에는 단순한 Chain of Thought 프롬프팅만으로는 한계가 있음을 의미합니다. 이를 극복하기 위해 추론 능력이 강화된(Reasoning-trained) DeepSeek-R1 모델을 활용한 새로운 평가 방법을 제안했습니다.
DeepSeek-R1은 명시적인 <think> 단계를 통해 평가 근거를 체계적으로 추론한 후 최종 판단을 내립니다. 이 방식은 일반 도메인 데이터셋에서 사람 평가와의 상관계수를 0.60으로 대폭 향상시켰으며, 특히 KoBankIR 데이터셋에서는 0.775의 높은 일관성을 달성했습니다. 이는 기존 G-EVAL 대비 약 2배 이상 개선된 수치입니다.
3. KobankIR 벤치마크
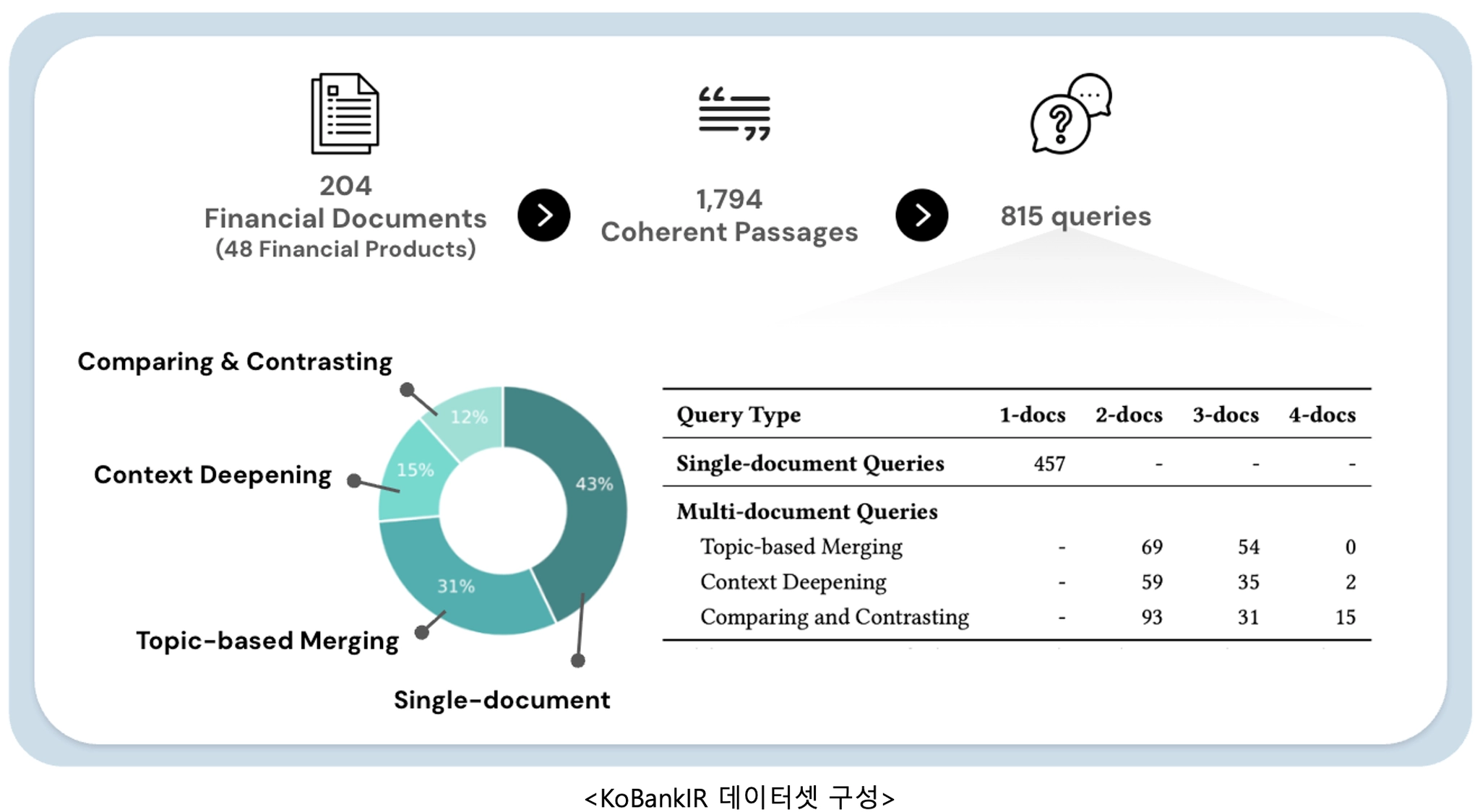
앞서 설명한 2단계의 쿼리 생성 파이프라인과 DeepSeek-R1 기반 답변가능성 평가 방법을 적용하여 한국어-은행 도메인의 KoBankIR 벤치마크를 구축했습니다. KoBankIR는 실제 카카오뱅크의 204개 상품 공시 문서를 기반으로 하며, 단일 문서 쿼리와 3가지 IR 시나리오를 반영한 다중 문서 쿼리를 포함하여 총 815개의 고품질 쿼리로 구성됩니다. 이는 실제 금융권에서 발생하는 복잡한 고객 문의 패턴을 반영한 최초의 한국어 금융 IR 벤치마크입니다.
4. 실험 결과
다양한 검색 모델(Sparse, Dense, Multi-vector, Hybrid)을 평가한 결과는 다음과 같습니다.
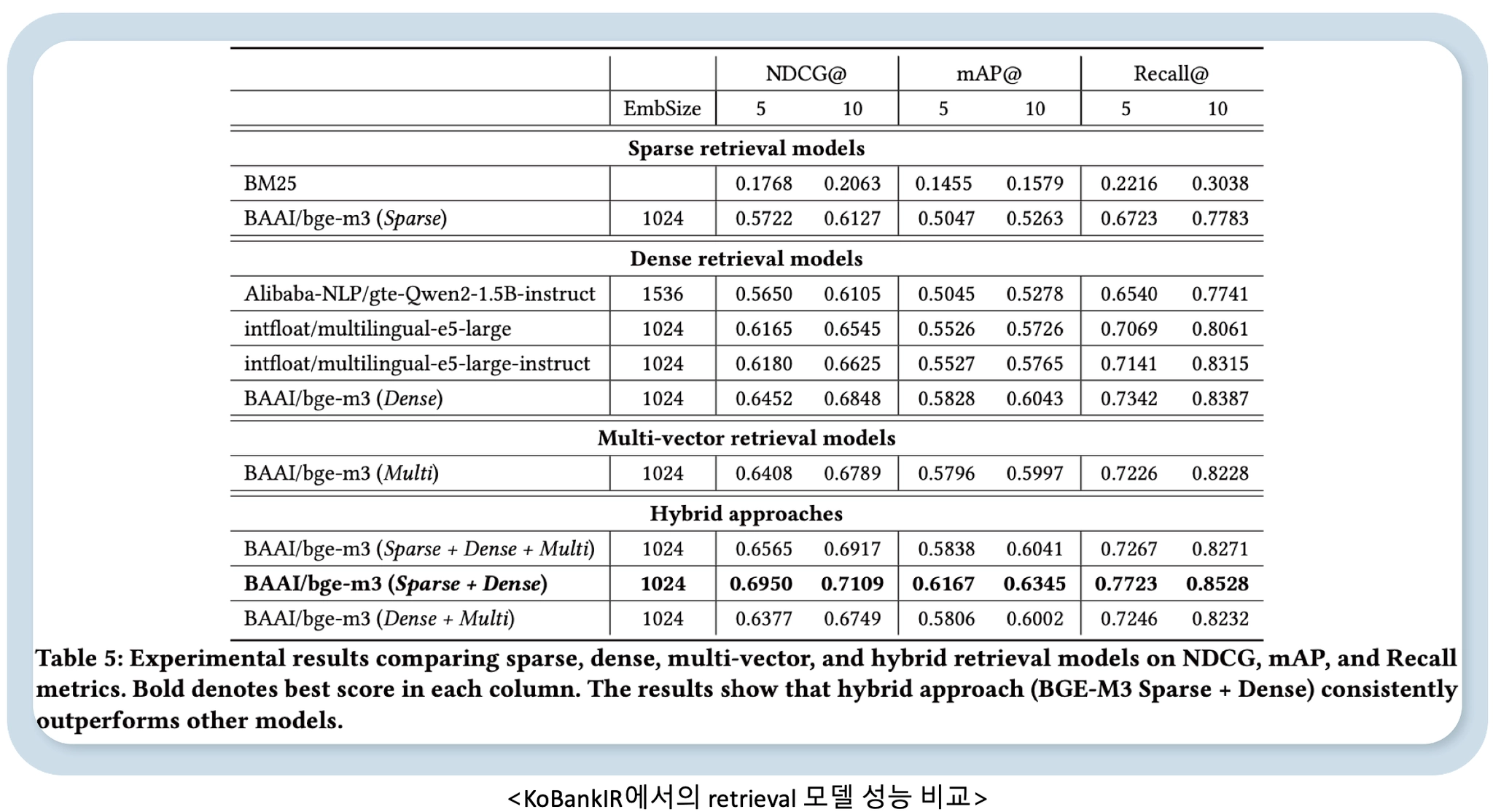
다양한 검색 모델(Sparse, Dense, Multi-vector, Hybrid)을 KoBankIR에서 평가한 결과, Hybrid 방식인 BGE-M3 (Sparse + Dense)가 NDCG@5 기준 0.6950으로 가장 우수한 성능을 보였습니다. 또한 문서 수가 증가할수록 검색 성능이 크게 저하되는 패턴이 관찰되었습니다. 단일 문서 쿼리에서는 0.749의 성능을 달성했지만, 2개 문서를 참조해야 하는 쿼리에서는 0.590으로 하락했고, 4개 문서 쿼리는 0.302까지 떨어졌습니다.
쿼리 유형별로 보면, Topic-based Merging과 Context Deepening에서는 각각 0.709와 0.696으로 비교적 양호한 성능을 보였습니다. 반면, Comparing & Contrasting은 0.414로 가장 낮은 성능을 기록했습니다. 이는 상품 간 비교·대조처럼 여러 문서를 종합적으로 읽고 복잡한 추론을 해야하는 질의가 현재 검색 모델들에게 특히 어려운 과제임을 보여줍니다.
이러한 결과는 현재 검색 모델들이 실제 금융 업무의 복잡한 다중 문서 검색 시나리오에서 한계가 있음을 시사합니다.
마무리
본 연구는 LLM 기반의 체계적인 쿼리 생성 파이프라인과 개선된 답변가능성 평가 방법을 통해 도메인 특화 IR 벤치마크를 구축하는 실용적인 방법론을 제시했습니다.
KoBankIR는 실제 은행 문서를 기반으로 한 한국어 금융 IR 벤치마크로서, 실무에서 자주 발생하는 복잡한 다중 문서 질의를 포함하고 있습니다. 실험을 통해 실제 금융 도메인의 복잡한 다중 문서 검색 시나리오에서의 현재 검색 모델들의 한계가 드러 났으며, 이는 향후 금융권 AI 서비스 고도화를 위한 검색 기술 발전에 발판이 될 수 있을 것으로 기대됩니다.
발표 현장 스케치
해당 연구는 ICAIF2025의 Oral Paper로 억셉되었습니다[2]. 저희 논문은 “Ethics and Bias in LLM driven Finance” 주제의 3번째 순서로 발표를 했습니다. 특히 은행 환경에서의 검색에는 어떠한 특징과 니즈가 있는지 물어보는 질문이 많았습니다.
•
만들어진 쿼리와 실제 유저의 쿼리끼리는 얼마나 유사한지?
•
은행에서 Ethics and Bias를 얼마나 중요하게 생각하는지?
•
이 벤치마크로 측정한 검색 모델의 차이가 RAG 환경에서는 얼마나 영향을 미치는지?
•
이러한 벤치마크를 기반으로 모델 평가 이후 모델 튜닝까지는 어떤 과정으로 진행이 되는지?
Reference
[1] Fu, W., Wei, B., Hu, J., Cai, Z., & Liu, J. (2024). Qgeval: Benchmarking multi-dimensional evaluation for question generation. arXiv preprint arXiv:2406.05707.
[2] Kim, H., Yoo, Y., & Kwak, Y. (2025, November). Query Generation Pipeline with Enhanced Answerability Assessment for Financial Information Retrieval. In Proceedings of the 6th ACM International Conference on AI in Finance (pp. 141-149).


카카오뱅크 금융기술연구소
Financial Tech Lab